
目次
■人工知能(AI)と機械学習

2022.09.09 2024.01.22 約4分
CADDi AI Lab の河合(ばんくし)です。キャディ株式会社 AI Lab Tech LeadとしてMLを事業に応用する業務を担当しています。
本日は大きく下記4つのトピックをお話します。
CADDi は製造業を変える企業です。説明が少し難しいので、製造業について何かをやっているベンチャー企業なんだなと理解していただければと思います。
Tech Blog や Speaker Deck、テックイベントを開催しています。応用事例をいくつも公開してますので、ぜひアクセスしてみてください。現在のAI Lab のMLエンジニアは9人で、DeNAやマッキンゼー出身の方であったり、Kaggle のGrandmasterや他社でのテックリード経験がある方が集まっています。また競プロ暖色プレイヤー達が集まるアルゴリズムに強いチームもあります。国際色豊かなチームで、今後新たなメンバー参加も決まっているので、今後は本日発表した以上のものができていくと思います。
現状は Python と Rust が共存しています。
データ管理、検索、インフラ周りも自分たちでやることが多くなりました。
この辺りは Tech Blog やイベントでオープンにしていければと思っています。ぜひCADDi の名前を覚えてもらえればと思っています。
ここからは本題の CADDi での Deep Learning 活用のお話です。先日リリースした製造業向けSaaS、CADDi DRAWER( キャディ ドロワー )では、アルゴリズムに Deep Learning とANN を使っています。
こういったことが可能なサービスです。
実際の Deep Learning のモデルに関しては深く触れられない部分があるのですが、マルチタスクの Deep Learning モデルを作っています。
CADDiは元々受発注事業をしていたので、社内にたくさんのラベル情報を保有しています。そのラベルをマルチタスクにトレインして「近さ」を定義し評価するのですが、「近さ」の観点が少し難しいので、社内の製造業の専門家にアノテーションしてもらっています。それをトレーニングの学習データとしてトレインして、中間層の出力を取ってきています。
OpenSerchやVertex、Maching Engine のようなベクター検索とテキスト検索のロジックを複合して条件検索ができるようにしています。
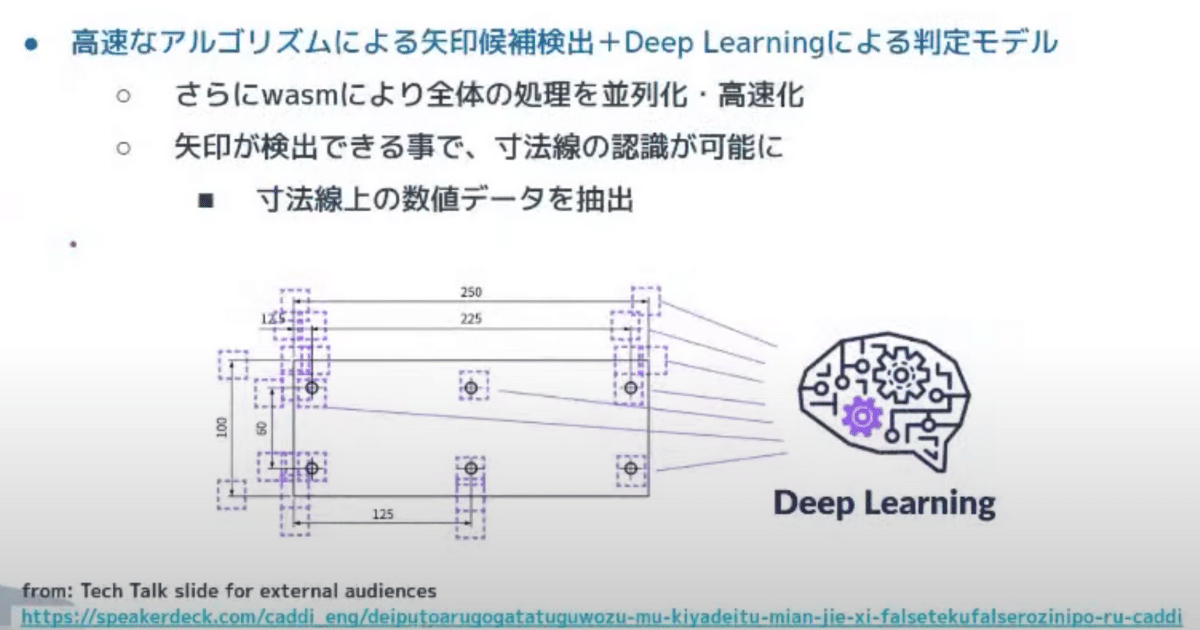
少し図面の情報抽出の話をすると、アルゴリズムを使って候補を検出して、その候補がターゲットであるか否かという二値分類をおこなう DNN のモデルみたいなこともやっています。
下の例は、矢印の認識に関連したものです。実際、Rustで Deep Learning のモデルを ONNX を通して読み込むことで、全体の処理がかなり高速になっています。
この矢印を読み込めると寸法線(250の記載がある部分)が読み込めるようになります。
サイズは価格や調達における重要データなので、細かなデータ抽出として Deep Learning モデルを作っています。
他にもシンプルだけど難しい分類や回帰のタスクをいくつか紹介します。多くは二次元の図面に対しておこなっています。
画像右側のRound barを削ったり曲げたりして図面を生成しますが、元の形状を分類する問題を解いていたりします。図面の中で明示的に数値で書かれていない、このあたりの情報を推定するといった回帰のタスクにもチャレンジしています。
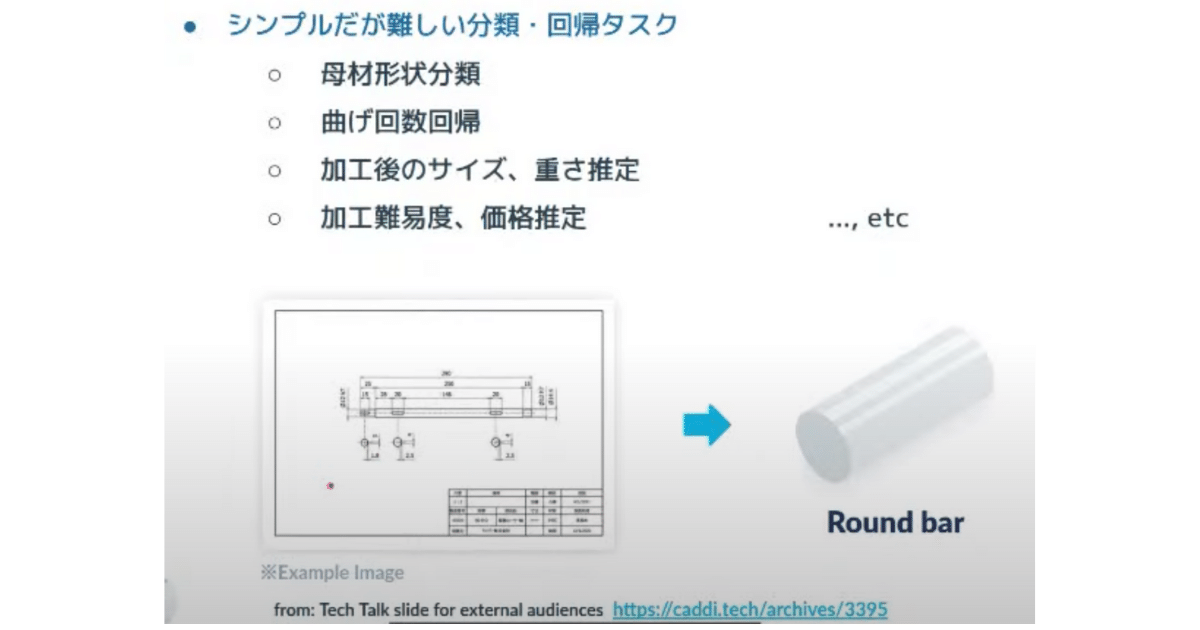
もう少し顧客に近いところでは、加工の難易度を図面から DNN で推定したり、価格を直接あてるようなことにもチャレンジしています。
少し2Dの話が続きますが、2Dの図面は基本的に3Dの CAD から出力されます。
出力時に図面に対してノイズが乗っていたりするので、ノイズ除去するようなモデルも作っています。これをおこなうことで、画像処理のアルゴリズムの性能向上を図っていたりもします。
Deep Learning の活用は、製造業界においてかなり広く、いろいろなタスクが存在しています。
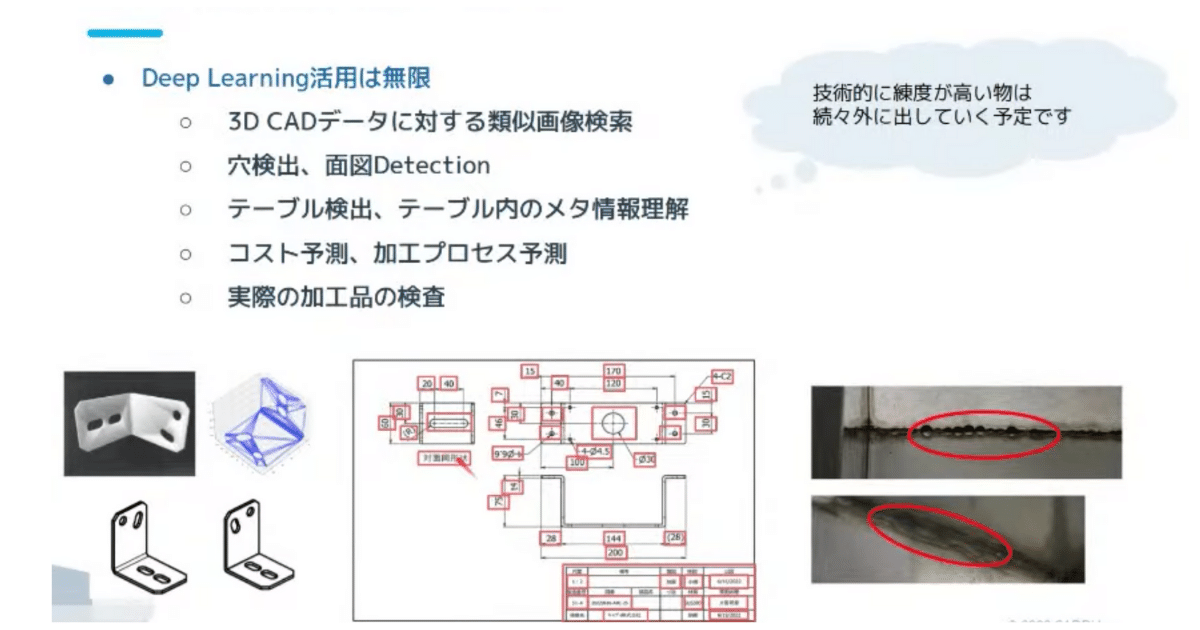
ここまでお話しした2次元の図面は、製造業界における設計より後ろのフェーズではかなり使われています。
最近では、3D の CADデータでも2次元と同様の技術が使えるのでは?ということで3Dの類似画像検索などのタスクを持っていたりします。
他にも下記のようなタスクがあります。
まだまだ実用化には至っていないものの、新しいチャレンジもおこなっています。もうちょっと技術的にもビジネス的にも練度が高まってきたら続々外に出していく予定なので、ぜひウォッチしておいていただければと思っております。
ここからはもう少し図面情報抽出の文脈で DNN 活用をテーマにお話します。この4月から自社で OCR を作るプロジェクトを始めています。
一般的な OCR だと、下の図にあるような特殊な記号(斜めに書かれているもの、特殊なフォントや記号など)が、どうしても出てきます。
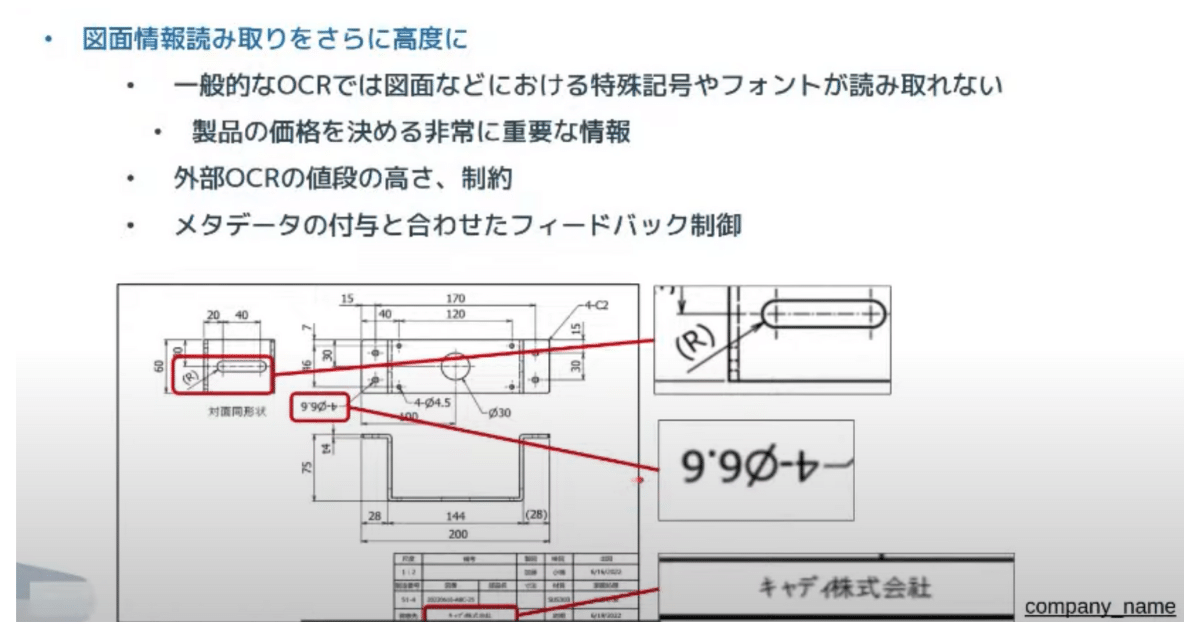
これが製品の価格を決める情報だったりするので、検査データとして重要です。なんとかこの図面に書いてある情報を正確に読み取ることができないか?が、大きな課題でした。
外部の OCR、例えば提供されている OCR API や外部のソフトウェアを購入するケースがあると思いますが、値段の高さや技術的な制約、リクエストの数、マシンスペックの問題をチューニングしやすくしたいという課題もありました。
加えて外部の API を使っていると、アップデートによってこちらのロジックっていうのが壊れてしまう可能性があるので、自社で持っておくっていうのは一つ強みになるだろうと。
OCR の結果に対して、それがどういう情報なのかをメタデータ付与したいというのが、最終的にやりたいことになっていたりします。
メタデータを付与するときの推論の結果を使って「この OCRの判定結果 ってそもそもこっちに補正できるのではないか?」みたいなフィードバック制御ができるようになっていくと、まさにこの図面の認識におけるパイプラインとしては理想の形状になるかなと考えています。
図面以外に対しても学習させて活用できるのではという将来的な構想も含めて、こういったプロジェクトをやっています。
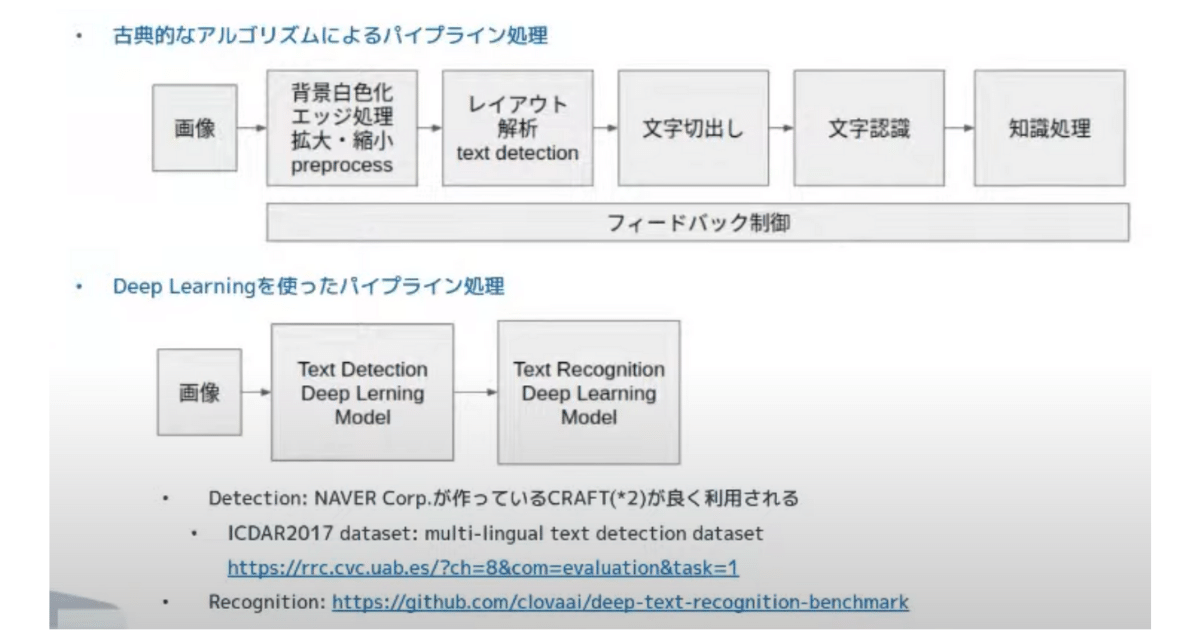
私は日本語の OCR のサーベイから広く始めました。大きく2つあるので紹介します。
いわゆる古典的なアルゴリズムを使って前処理し、レイアウト解析をして文字の部分を切り出して認識にかける(テンプレートマッチをして認識する)ロジックです。
最近大きく精度を伸ばしてるのが Deep Learning の手法です。
私が学生の頃は、コンピュータサイエンスの総合格闘技といいますか、画像処理を含めいろいろな処理が OCR の難しさであったかなと思いますが、その土壌はもうほとんど Deep Learning に移ってるかなという印象です。
直近ではテキストの
この2つのモデルを作って、それを繋げるのが一般的な OCR のフローになっています。
Detection は、NAVER Corp. が作成しているCRAFTと呼ばれるフレームワーク(OSS)がよく使われている印象です。Recognition も、NAVER Corp.の CLOVAチームが公開している Recognition ベンチマークというものが、おすすめです。Detection と Recognition 2つを作って管理する必要があるのが、現代OCR かなというお話でした。
「いやいや、もう少し簡単に使い始めたいですよ」「エンジニアとしては早めに使い始めたいですよ」という部分もあると思うので、そういうところもサーベイしています。

よくあるAPIでは、この辺りが多言語でかつ精度が高いので、汎用的に使いやすいでしょう。
自社開発する場合は、もう少し OSS を調べたり、モデルを自前で実装する形になると思いますが、最初によく調べて出てくるのは tesseract、OCR かなと思います。
検索すると1番上に出てきますね。OpenCV にも導入されています。LSTM あたりが導入されてから更新が止まっているので、現状、高い精度が出せるかというと少し難しい部分があるかなと思います。
こちらも人気が高いです。 Baidu が開発しているPaddlePaddle と呼ばれる PyTorch とか TensorFlow みたいなニューラルネットを扱うフレームワークがベースです。私も試してみましたが、文字コードの問題などがあり日本語対応が少し大変かも知れません。
あと TensorFlow とか keras に馴染み深い人は良いかも知れません。ただ最終更新が1年前ということで少し使いにくいかも知れません。
我々が結局行き着いたのはEasy OCRです。Detection と Recognition のパイプラインを備えているもので、日本語の事前学習モデルもあるのですぐ試せます。
もう少し EasyOCR のお話をしましょう。PyTorch ベースのパイプラインを作成してくれるフレームワークになります。Deep Learning では Detection と Recognition が必要だとお話しました。EasyOCR では Detection は CRAFT を活用し、Recognition は ResNet や CTC が使われており、そこから複数の検出結果を出して一番良さそうなものを beam search で探索するといった実装になっています。
下記の図にあるように各モデルを別のモデルに入れ替える作業が、結構簡単です。PyTorch で書かれたモデルとトレーナーとかデータローダーとかを入れ替えるだけで実装可能です。
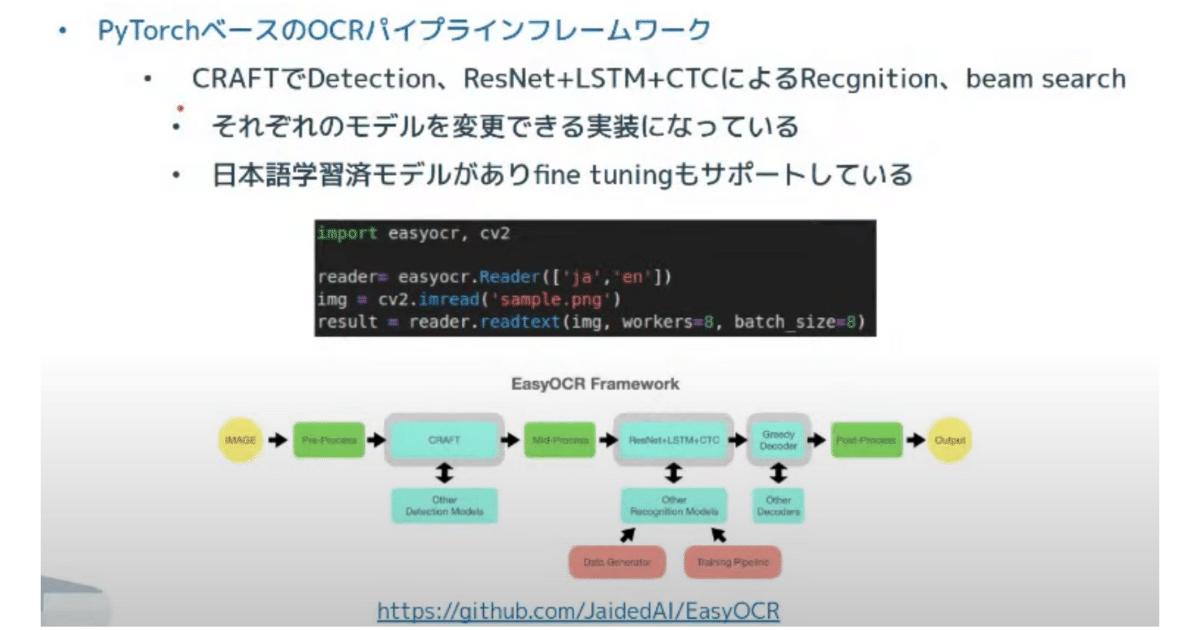
日本語の学習済みモデルもあるので、たった3行で最初の実装が終わりますし、そこから fine tuning もメソッドとしてサポートされているので、矩形と文字のデータっていうのがあれば、テキストを少しデータのドメインにフィットさせた OCRモデルを作ることができます。
どのようにCADDi の OCRプロジェクトを進めていったのかお話します。
受発注の事業で蓄積したデータを学習データにして、いくつかの APIやOSS、 Easy OCR の学習と評価を検証しました。
ここは知り合いの Kaggle Masterに業務委託をお願いして「これを調査した時点で一定のleak/over fit を許容すれば、Easy OCR が高い精度を出せるよね」ということを確認しました。
ここでいう leak/over fit ですが、特定の会社や特定の文字、特定の文章みたいなところにフィットしてしまって、そこのクロスバリエーションを変えると精度がでないみたいなことを検証していきました。
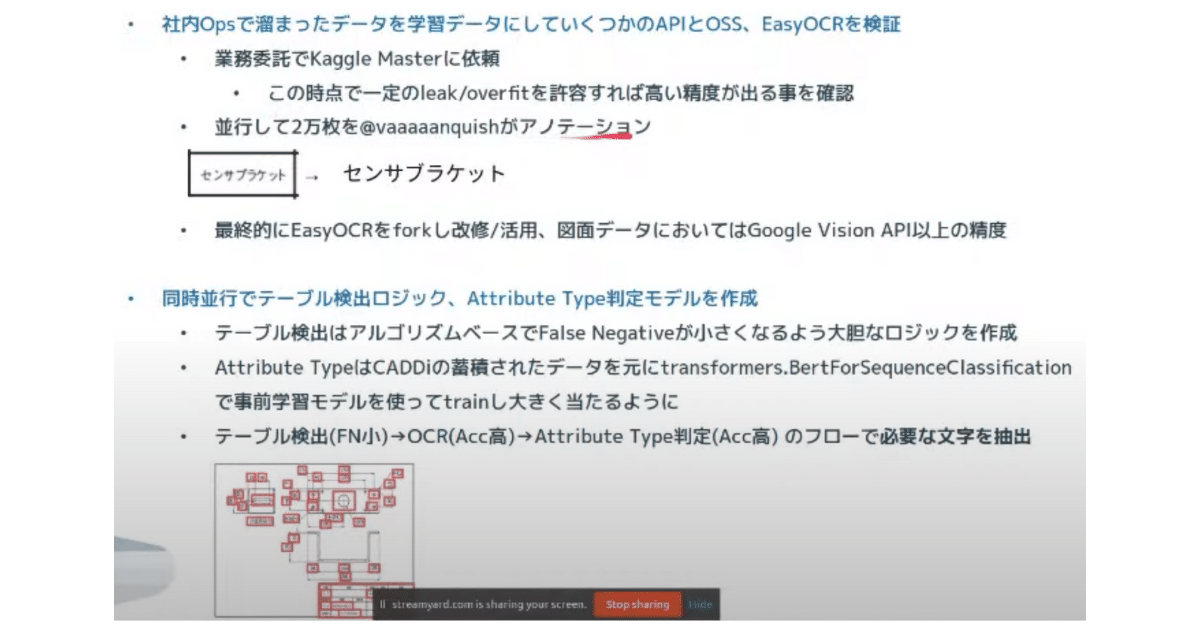
そうなるとやっぱりデータセットの多様性が必要だよねという話になり、並行して私が2万枚ぐらい画像をひたすら見る作業(アノテーション)をしました。最終的にはもう Easy OCR のコードを fork して改修して、活用する形で図面のデータにおいては Google Vision API 以上の精度が出るようになってきています。
さらに同時並行でもう1つ、先ほど OCR Project の目的が複数あるよって話をしたと思いますけど、テーブルの検出やAttribute Type の判定っていうところもやっていたりします。
今回はテーブルの検出を Deep Learning モデルではなくアルゴリズムベースで行なっているので説明を省きますが、なるべく False Negative が小さくなるようなロジックを作っています。
Attribute Typeの判定というのは出てきたOCRの結果が会社名なのか加工方法なのか、値段なのかサイズなのかを当てる、といったモデルを作っています。こちらもDNNを使っています。こちらも過去からBigQueryに蓄積された手入力のデータをラベルとして活用してBERTのモデルを簡単に学習させて精度が出るようにしています。先程、フィードバック制御の話をしましたがテーブル検出では低い精度でもいいから、多く検出できるようにして、そこにOCR、テキストのDetection と Recognition をしっかりかけて、ここの精度はなるべく高くします。そのうえでAtribute Type判定をし、それぞれ必要な情報とそれに紐づいたメタデータっていうのを作れるみたいなところまで進んでいます。
1つの DNNモデルではなく、複数の方法を組み合わせるのが OCR の非常に重要なところです。
どのAPIにするか、インフラの構成にするのか、を考えるのはDNN使用のうえで難しいところではありますが Deep Learning の応用としては、非常に面白いところかなと思います。
1. Deep Learning の製造業応用は無限
Deep Learning の製造業応用には無限にタスクがあります。それらを活用するための過去データや土壌があります。
2. OCR に本気で取り組んでいます
OCR Project は結構面白いです。複数の DNNモデルとかを組み合わせて図面の認識に取り組んでいたり、特殊記号への対応方法、図面の翻訳など課題が山積みです。
これから CADDi は国際化していきます。JIS規格 だと国際的に通用しないので、国際規格や規格言語の翻訳、規格の標準化などのタスクもプロジェクトの一環かなと思っています。

VPoE
高専にて電気情報工学を学んだ後、大学編入。機械学習理論に関する基礎研究を行う傍ら、株式会社Usageeにて機械学習アルゴリズムの実装をアルバイトとして経験。2016年、Sansan R&D部門に入社。画像認識エンジンや自然言語処理APIを開発。その後Yahoo! JAPANに転職。ヤフオク!機械学習モデリングチームのリーダーとして開発、マネージメントに従事。2019年2月よりエムスリー株式会社、機械学習エンジニア。MLOpsやチームの環境整備、プロダクト開発を行う。2022年、CADDi株式会社にジョイン。AI LabにてTech Leadとしてチーム立ち上げ、マネジメントを経験。エンジニア採用チームを推し進め、Tech HR Leadを兼任。現在はエムスリー株式会社に出戻り、VPoEとして組織作りに邁進中。趣味では開発ギルドBolder'sの企画、運営、開発者としての参加や、XGBoostやLightGBMなど機械学習関連OSSのRust wrapperメンテナを務める等の活動を行っている。学生時代の油にまみれたロボコン経験から、情熱的な場面やハードな書籍、対話が好き。


