ITエンジニアのキャリアに本気で向き合うメディア
ITエンジニアのキャリアに本気で向き合うメディア
目次
■キャリアとスキルアップ

2022.06.21 2023.12.14 約6分
Forkwell が主催する技術イベント「Front-End Study」。2020.12.15 開催のテーマは「メタ・パフォーマンスチューニング-Core Web Vitals-」です。
など注目の内容!

古川 陽介です。普段は Japan Node.js Assosiation の代表理事をやっています。会社はリクルートで活動しています。最近は Chrome Advisory Board で委員会のメンバーに選ばれていたり、イベントの開催もしています。JSConf.JP は2020年にできなかったので、2021年にやろうと思っています。
早速ですが、ここ最近パフォーマンス周りの更新がブラウザを中心として多いです。特に Web Vitals 周りが多いため、この辺の話から始めていきます。
Web Vitals はGoogle が提唱する新しい UX の指標です。主に以下の3つのポイントがあります。
これらの指標は変わり得ることが最初から示唆されています。Core Web Vitals 2021 で変わるという話が出ていますし、metrix や thresholds は最新の研究によって変わると書かれています。Chrome Dev Summit でも Future of Web Vitals のセッションのなかで早速変わることが発表されていました。
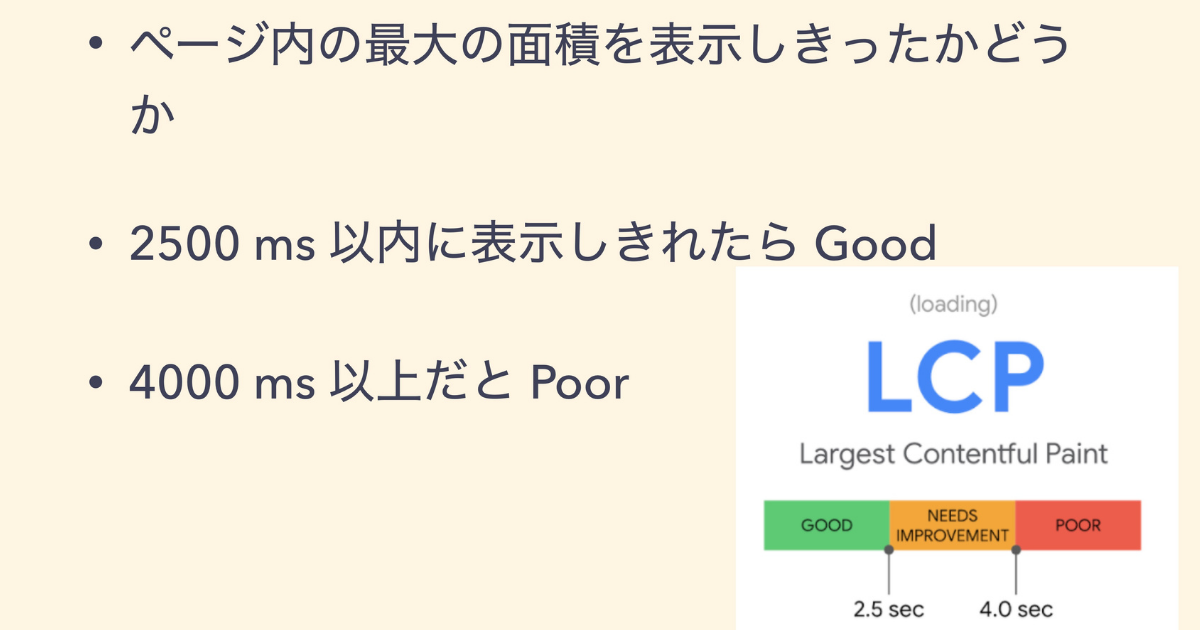
Largest Contentful Paint(以下、LCP) は、ページ内の最大の面積を表示しきったかを指します。よくあるのはヒーローイメージやロゴなどのページのなかにある最大の面積を表示しているかです。
2.5秒以内は Good、4秒以上だと Poor として評価されます。
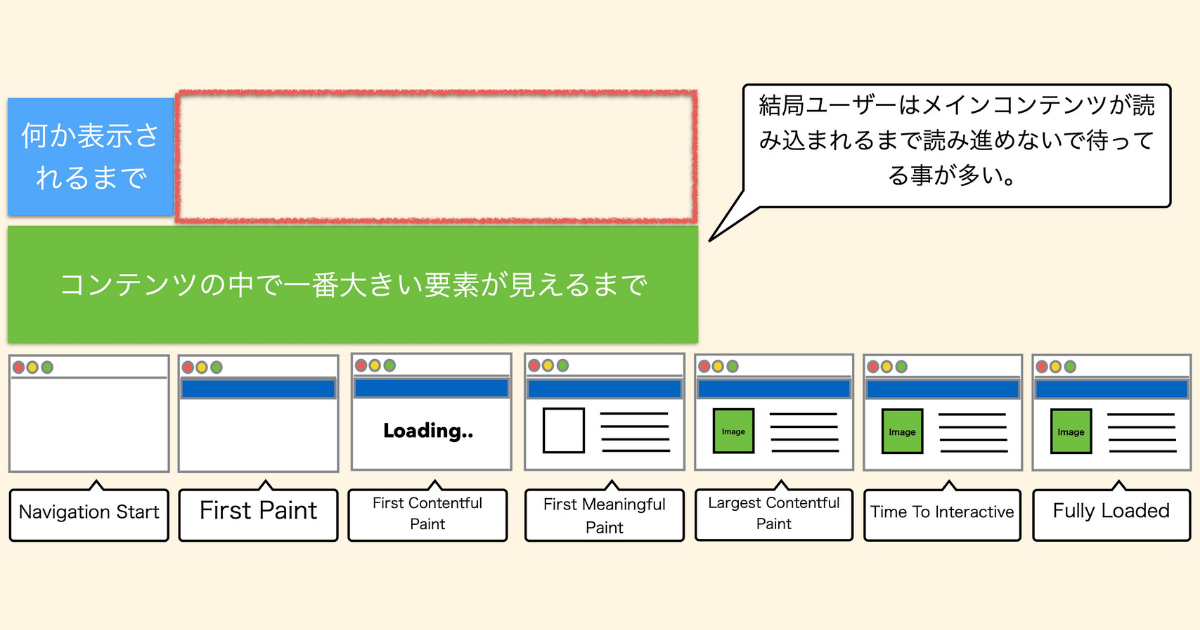
ここでブラウザのレンダリングが始まるまでの話をします。
図の左側から
コンテンツの中で一番大きい要素が見えるまでが、 LCPです。ユーザーはコンテンツのなかで一番大きい領域が表示されるまで待ってしまうことが多いため、LCPが指標となっているのです。
LCP に関しては First Contentful Paint(FCP) も指標に入れるとされています。
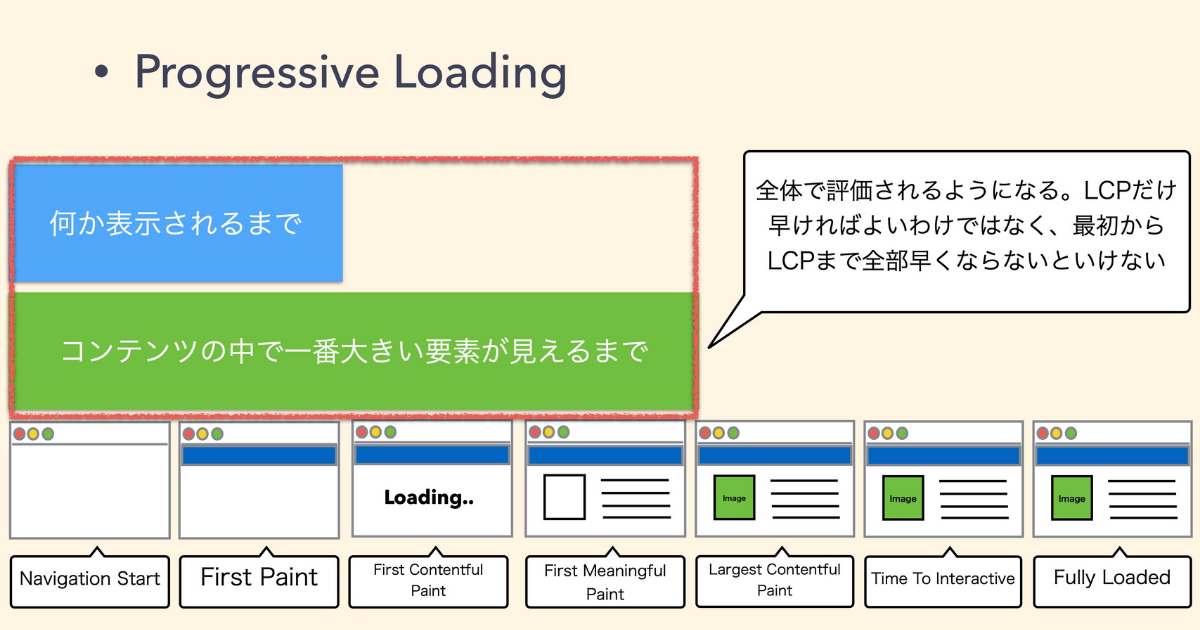
コンテンツの中で一番大きい要素が見えるまでが、 LCPです。
これからは何かが表示されるまでの時間も早くなければなりません。全体で評価されるようになったため、指標としては厳しくなっています。

改善ポイントはいくつかありますが、一番大きいのはサーバーのレスポンスタイムだと言われてます。
サーバーがレスポンスするまでの時間が遅かったら、そもそも話になりません。リクエストから何かしらのレスポンスが返ってくるまでの時間がとにかく早くないといけません。
JS や CSS などの render blocking resource はないことが望ましいです。Client Side Rendering も、JS がロードされてから出ないとコンテンツが表示されないので、なるべく避けたほうがよいでしょう。
またヒーロー画像(1番トップに出てくるような画像)は、Preload しておくことがLCP改善に必要だと言われています。
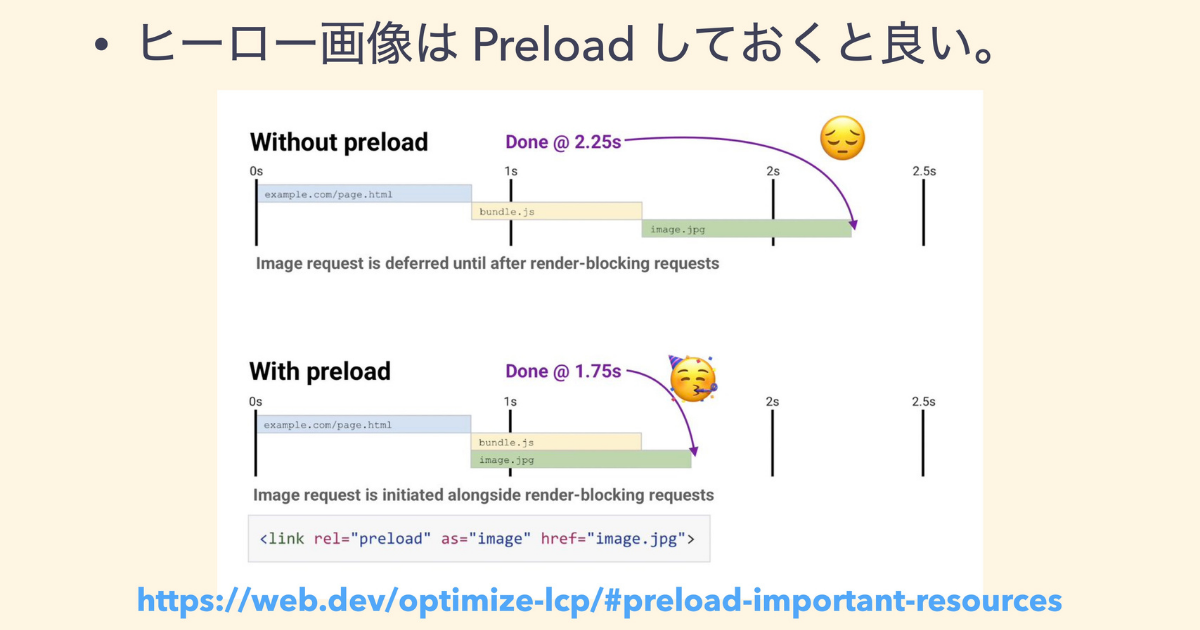
ヒーロー画像を Preload しておくといい理由を解説します。
Largest Contentful Paint を最適化する
例えば元々 Preload がないと、CSR などをやってるときに JS がロードされ、画像がロードされてから表示されるため、上記例で2.5秒だとギリギリになってしまいます。
しかし、Preload しておけば、最初のほうから JS のロードと一緒に画像のロードも始めることができるので、最終的な LCP が出てくるまでの時間が早くなります。

First Input Delay(以下、FID) は、ページが入力に反応できるまでの時間を指し、100ms以内だとGood、300mm秒以上で Poor と判定されます。
実は100msは FID の時間としてはすごく長いので、かなり甘い指標だといえます。
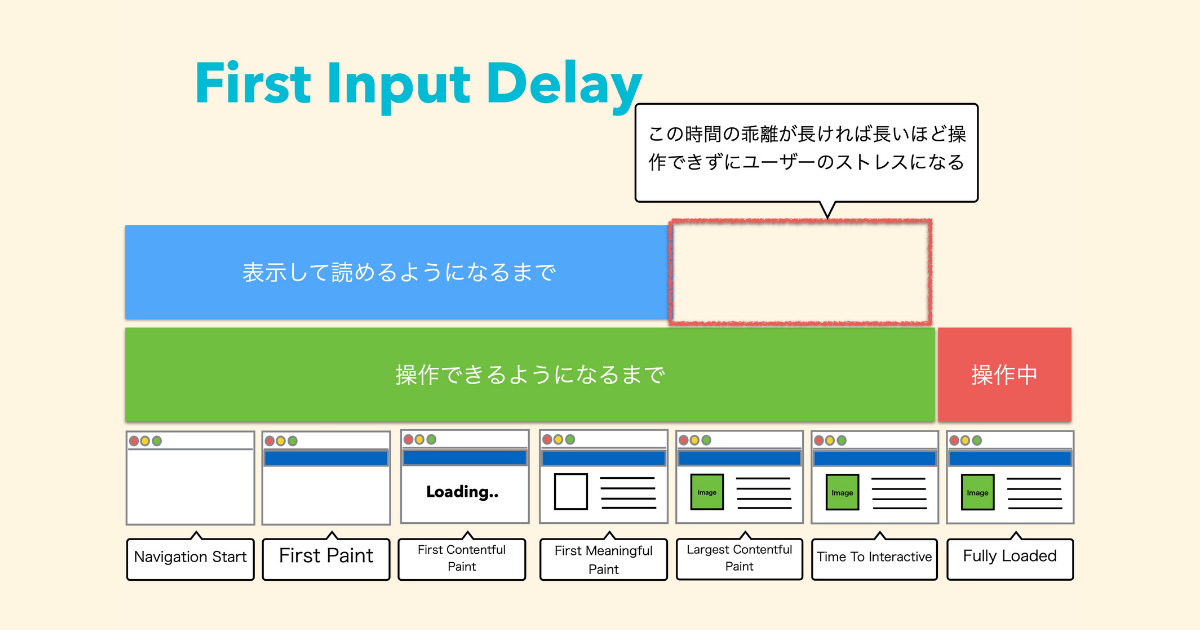
表示してから読めるようになるまでを First Meaning Fullpaint とよび、そこから操作ができるようになるまでを Time to Interractive といいますが、見えるのに操作できないのはストレスが溜まります。
これを100ms以内にしなければいけないのが FID です。
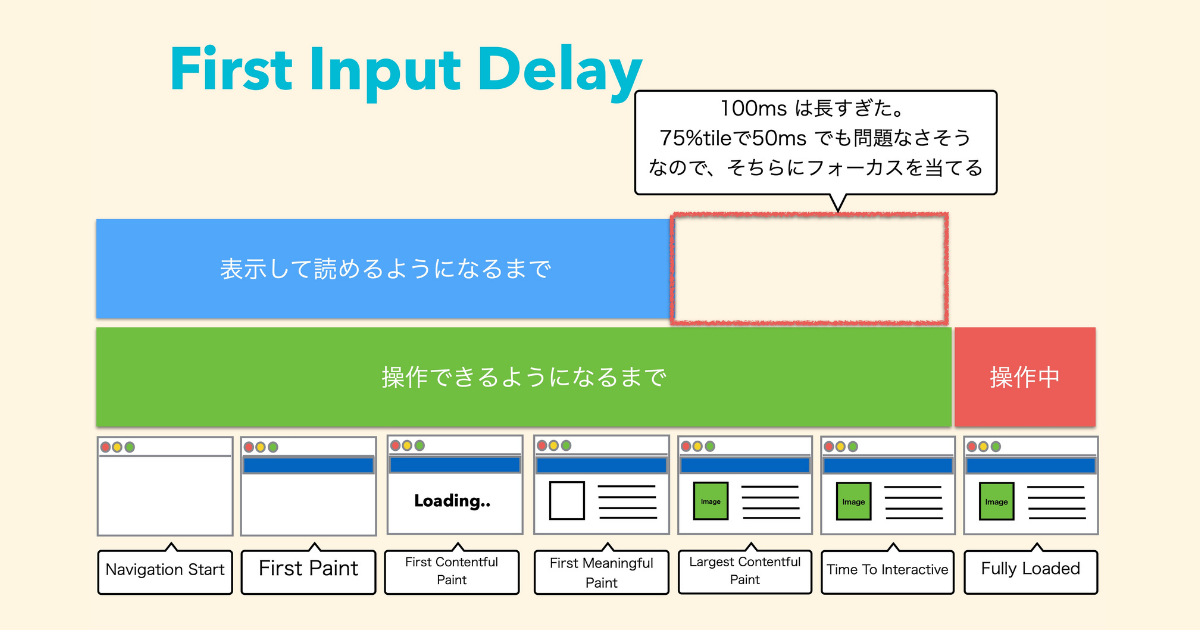
これはシンプルに100msでなくなり、50〜75msをしきい値にするとされています。
これまで100msと、かなり余裕があったと思いますが、詳しく調べてみると75%tile で50msぐらいだったので、それでも問題ないのではないかと言われていました。
しかし、残りの25%の人たちが100ms以上かかっていることからも基準をマジョリティのほうに合わせていた形となっています。

そもそも読み込まれてる JavaScript を小さくしていきます。
主におこなわれているのが、メインスレッドです。メインスレッドがずっと読み込み中の状態だと何もできなくなってしまうので、それをなるべく避けてあげる必要があります。
そのなかで一番大きいメインスレッド阻害要因の1つが JavaScript です。JavaScript をどうやって読み込むかを検討していきます。defer/async などをつける、code split で JS を分ける、 polyfil の利用を控えてモダンブラウザ向けの Bundle JS を作るなどが手法としてあります。
それでもどうにもならないときは WebWorker を使ったりします。

Cumulative Layout Shift(以下、CLS) は、ページが読み込みから領域がずれた場合のズレ幅の和です。
0.1以内の Layout Shift スコアなら Good、0.25以上なら Poor と判断されます。

Layout Shift スコアを計算するには、どれだけの大きさのエレメントが動いたかを示す impact friction と、どれだけの幅を動いたかを示す distance friction をかけて算出します。
そして、Layout Shift の総和が CLS となります。
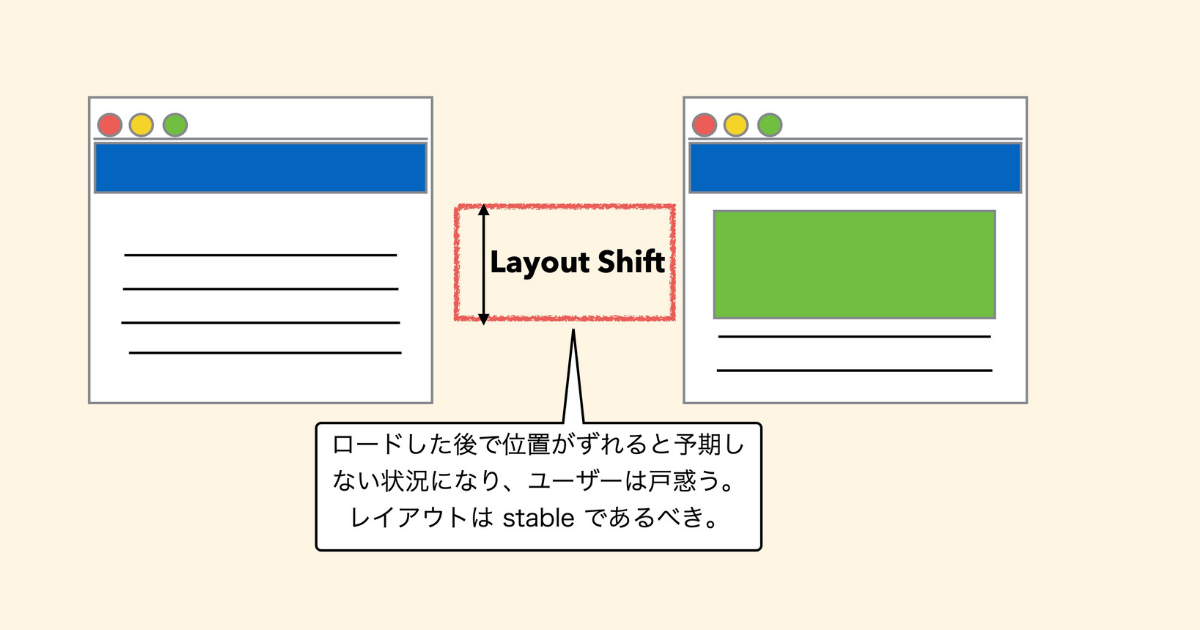
ロードしたあとで位置がガタンとずれてしまうとユーザーは戸惑います。
広告などをたくさん読み込んでいるサイトにありがちですが、ソートしたときに予想した領域から少しグッとずれて、間違えて広告を押してしまうことがあります。これではユーザーが戸惑うので、基本的にレイアウトは変わらないことが望ましいです。

広告以外にもいろいろ起きてることがあります。よくあるのは画像の縦幅を指定しないことです。
また、動画やアイフレームも縦幅横幅を指定しないでロードし、ロードが終わったあとにサイズが決まると、その分だけ下に出たりするなどのずれが生じます。
おもしろい変更が入っています。今まではレンタリングされきるまでのシフトがどれだけ起きるかが基準でした。しかし、長期間生きてるページ、例えばシングルページアプリケーションのようなものにも同じスコアが適用していくと言われています。
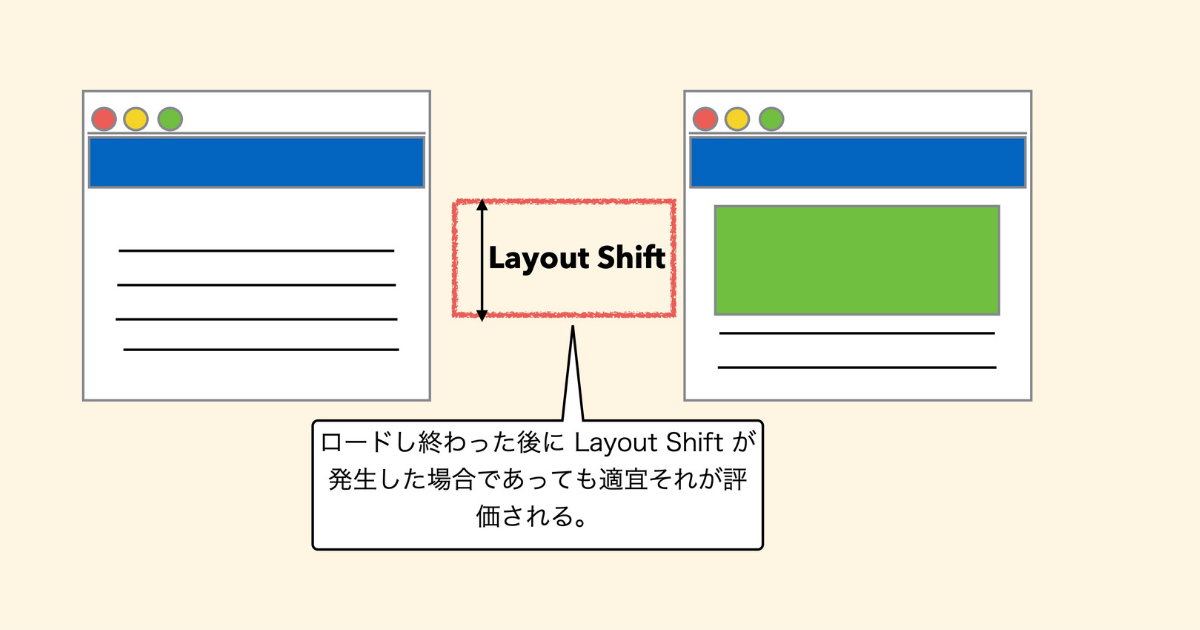
つまりロードし終わったあとにレイアウトシフトが発生したとしても、それが適宜評価されるようになっています。
例えば、ロードが終わり、レイアウトが決まってるはずなのにシングルページアプリケーションでポチポチやっていて、そのときにロードが終わりきってズレが起きてしまうと、そのズレも評価対象に入ります。
LCP の変更もそうですし、CLS の変更もそうですが、初期表示時点で評価するスタイルからナビゲーションやスクロールなどの操作を含めたトータルの評価が今後は鍵になってくると考えられます。
このように Core Web Vitals といっても指標も変わりますし、やることも結構変わってきています。

また、WebFont もFOUT や FOIT と呼ばれる読み込まれるまでに違うフォントが出てしまったり、真っ白のフォントになってしまうなど、若干レイアウトシフトが起きる場合があります。
最近 Cache Partitioning と呼ばれている機能が各種ブラウザベンダーに実装され始めています。
今まで Public CDN は WebFont や JS で1回ダウンロードしておけば、そのキャッシュが効きましたが、読み込まれる元のサイトがどこかという部分に対してパーティショニングされていたので、 Public CDN でロードする旨味が落ちてしまいます。
使わなくてもよい裏付け → この記事では、実際に自前で作って自前で読み込むほうが早かったという結果が出ています。
Time to Say Goodbye to Google Fonts: Cache Performance¸
過去も現在もある指標で、PRPL や RAIL というパターンがありますが、覚えてる方はいますか?
覚えてない人が多いのではないかと思います。2016年ぐらいにあった Google の指標で PRPL の P は Push を表しています。
この時代の Push とは、http2 のサーバープッシュの話なので時代を伺えますね。2016年は PRPL がもてはやされていた時期ですが、それも変わってきてしまい、RAIL もあまり聞かなくなってしまいました。
過去にあった指標も常にアップデートされている状態です。
Web パフォーマンスは生き物と一緒だと考えています。企業が変われば改善ポイントも常に変わって進化していく状況だと思います。
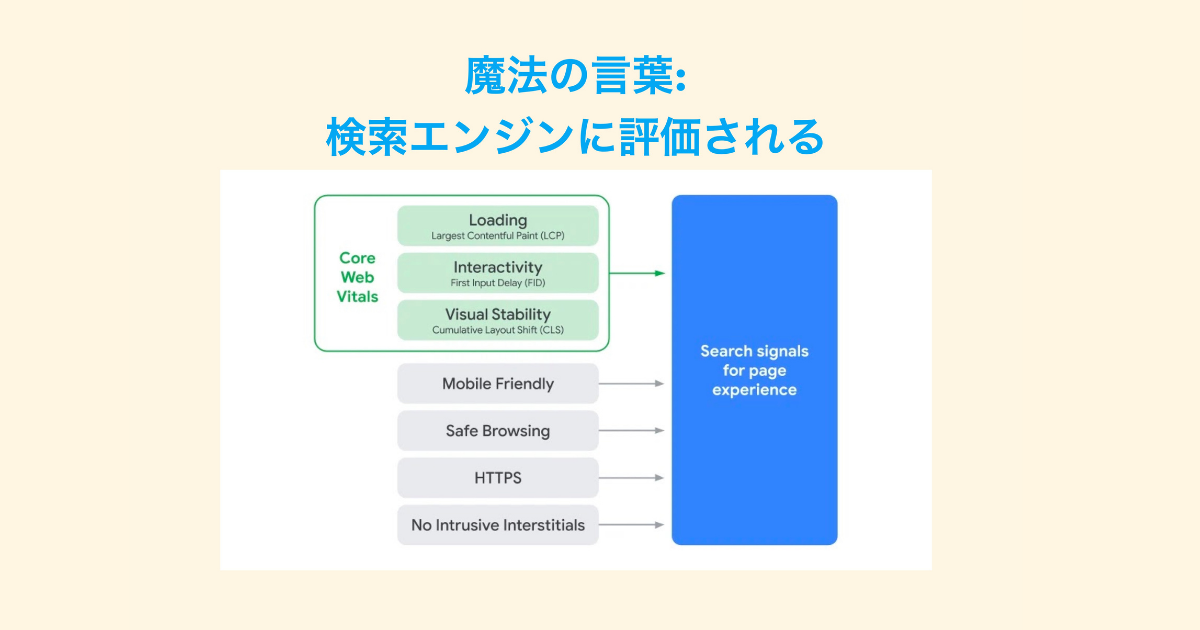
最近 Core Web Vitals がもてはやされてるのは、この影響が一番大きいと思います。
それが「検索エンジンに評価される」ことです。この魔法の言葉によって Core Web Vitals はさまざまなところで耳にするようになりました。しかし、検索エンジンばかりに振り回されてはいけないとも思います。
検索エンジンに評価されるからパフォーマンスチューニングをやるというのは手段と目的が変わっています。
本来はユーザーの体験を向上させるためにパフォーマンスをあげ、その結果検索エンジンにも評価されるのです。
本当は誰のためにやっているのかというと、ユーザーのためです。ユーザー体験を向上させるためにパフォーマンスを上げていく必要があり、その結果として検索エンジンにも評価される流れが正しいと思います。
検索エンジンが先にきてしまい、ユーザーのためではないという話になると、いろいろなハックができてしまいます。LCP をとりあえず上げとけばいいだろうとハックしてしまうと、結局その都度イタチごっこみたいになって対応せざるを得なくなります。
Core Web Vitals の話も重要ですが、それはそれとしてユーザーの体験を向上させるためのものだと考え方がブレなければ、そもそもやりすぎることもないでしょう。
ここから、我々はどうすべきかを3つ話します。
なるべく見える化しましょう。普通に聞こえて、なかなか実行するのは難しいです。
見える化 = ツール になりやすいですが、可視化ツールを入れるだけでなく、自分で作ることも視野に入れていくといいのではないかと思います。
見えないものは測れません。そして、測れないものは改善できないので、見えていないものを見えるようにしたほうがいいです。
ユーザーの体験がユーザーのためのものだとしたら、ユーザーの体験を見えるようにしてあげる必要があります。
既存のツールはたくさんあります。1-4までのツールは僕らも使っていてとても便利ですが、5で紹介する最近でた AutoWebPerf にも注目です。
1. SpeedCurve
2. Lighthouse CI
Lighthouse を CI 上で動かして遅くなっていることをラボデータで確定にできます。
3. CrUX
ビッグデータ上に Chrome のユーザーエクスペリエンスのデータが上がっているので、本当に早いのかをフィールドデータで見ることができます。
4. Page Speed Insights
フィールドデータとラボデータの両方を見ることができます。
5. AutoWebPerf (最近でた総合的なツール)
これは上で紹介したツール機能が総合的になっているものです。これを使うと、そのまま結果を CSV でダウンロードしたり、いろいろなことができて、そこからまた自分たちで解析できるツールです。
既存ツールも重要ですが、最近は UI が高度化していると思います。例えばシングルページアプリケーションで作るなど、リッチな UI が増えてきています。単純に読み込むだけの時間を見るだけであれば、既存ツールで問題ありませんが、単純な尺度だけでは足りなくなることもあるでしょう。
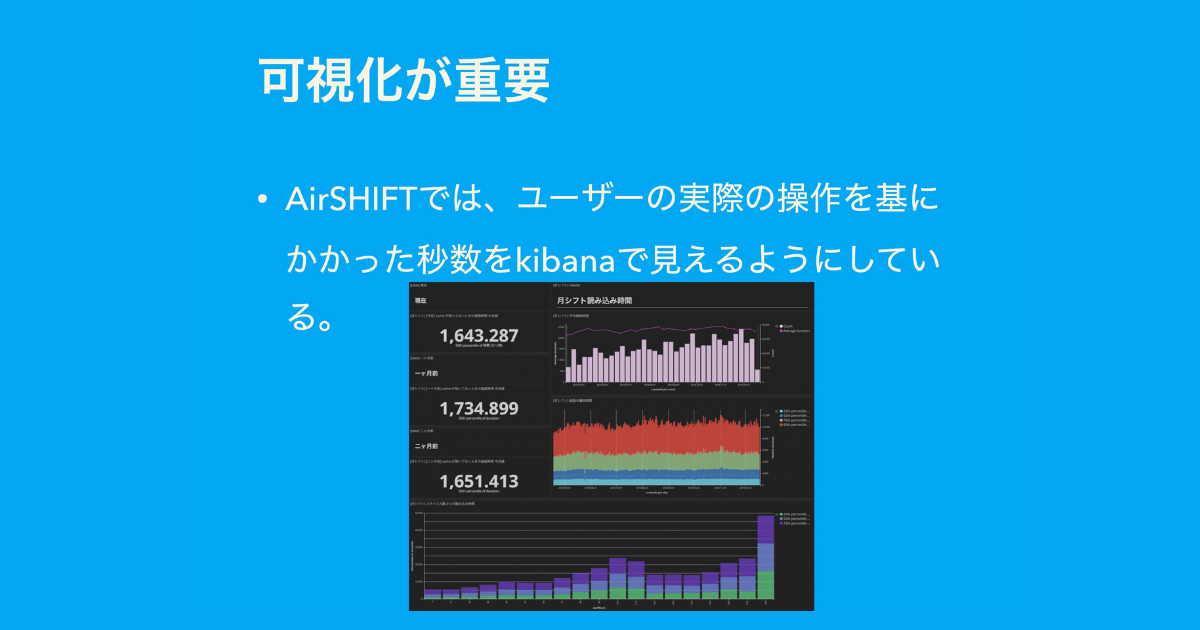
ここで、弊社の事例を紹介します。AirSHIFT というシフト表を管理するツールがあり、ユーザーがシフト表を読み込んだ時間やシフト表を作っている時間も Redux のアクションをもとに、アクション単位で記録しています。
その結果をもとに、kibana で可視化し、今何秒かかっているかやどれくらいの読み込み時間がかかっているかも見えるようにしています。そのため、より踏み込んだ解析をしています。
既存のツールで取れるメトリクスは最低限必要なものとして、ユーザー体験そのもののパフォーマンスを可視化することで、より体験に直結した時間が取れます。そしてその時間を解析・分析すれば、ユーザー体験の向上を目指すことができます。
なるべくモダンなフレームワークに乗ったほうがいいと思います。よく使われているフレームワークにはベストプラクティスが詰まっていることが多いです。

例えば Next.js や Nuxt.js などのフレームワークがそれぞれありますが、すでに JS の Code Split や Server side Rendering、Static Site Generation などの現代のベストプラクティスは Next.js や Nuxt.js が大体やってくれています。
また、next/link などで読み込み先のページリンクが見えたら、先読みしてくれたり、Next.js の機能だと、ビルトインでアンプが組み込まれてたり、アンプのページを作りたいと思ったらビルトインを使ってそのまま作れたりします。

また、新しい機能で、Next.js の V10 ぐらいから入った機能ですが、next/image という縦横幅を指定することで Layout Shift をおこさなくする機能が入っています。さらに画像の最適化をおこなう仕組みをビルトインで提供しています。
また、reportWebVitals という組み込み関数が入っていて、WebVitals のメトリクスが取れます。
WebVitals はあまり知られていませんが、メトリクスをとる仕組みがオープンソースソフトウェアになっていて、読み込みの時間などが取れます。これを使えば自分たちで可視化ツールなどを導入しなくても Next.js のなかでメトリクスが取れてしまいます。
パフォーマンス改善が職人芸になると職人が途絶えた瞬間に改善が見込めなくなってしまい、ハイスキルを持った人しかできない状態になります。
そのため、なるべくコモディティ化していきたく、リクルートでは、スピードハッカソンをしたり社内 ISUCON したりなど、性能の部分は民主化しています。

例えば、ウェブフロントエンドだけでどこまで Lighthouse のスコアを上げられるかを競う大会を開いています。
これは楽しみながら学べるので、すごくいいと思います。短期的に性能に関するナレッジを実践形式でためられるので、そこが売りです。
こうやってなるべく知見を共有していくと、性能やいろいろな機能要件を文化にする必要があると思います。性能のパフォーマンスチューニングを特定の人しかできない状況は避けて、全体的な文化にする必要があります。

パフォーマンス自体は生き物で、指標も変われば改善ポイントも変わると思います。また、パフォーマンスはユーザーのためのものなので、ニーズによって見るべきポイントも変わります。
開発者としては、できるだけ見える化をおこない、モダンなフレームワークに乗っかり、パフォーマンス自体を短期的な改善活動で終わらせずに文化にしていく必要があると考えています。
Q&A

potato4d
LINE株式会社
開発マネージャー&合同会社ElevenBackのCEO / Nuxt.js official module creator
古川:まず見える化が重要です。ただ先ほどの kibara でグラフを出すなどまではいきなりできないと思いますので、PageSpeed Insights や Lighthouse のスコアを見るところからやってみて、その中のさまざまな情報を見ていくといいと思います。
例えば、どのようなボトルネックがあり、どういった改善が必要かなどもわかるので、そこから勉強していくのが一番わかりやすいかなと思います。
ただ、そればかりをやりすぎてしまうと、今度はユーザーの話ではなくなってしまうので、先行しすぎるのはよくないです。第一歩としてはじめてみてください。
古川:ちなみに potato4d さんの現場では何かやっていたりするんですか?
potato4d:会社でいうと、例えば LINE News などは毎日 Lighthouse の結果が Slack Bot に送られてきて、悪くなっていないかを常にチェックする現場もあります。
古川:すごい実践的ですね。
potato4d:正直、弊社の場合はスマートフォンのインアップブラウザで動くものが多いので、外部ツールに頼りづらい部分があります。ただ、Lighthouse CI だったらそのなかでも動かせたりするので、結構使っています。
古川:たまに Lighthouse CI は上下幅の変動が激しい場合もありますよね?
potato4d:そうですね。私自身は LINE News チームではないですが、しっかりウォッチしながら結果を見ています。
古川:うちの会社は、SpeedCurve をよく見ています。また、競合との比較もよくやっています。比較することで競争意欲が掻き立てられるので。
古川:非機能要件のなかでも、パフォーマンスやアクセシビリティは理解が得られにくいところだと思います。
そこに関しては、草の根活動的に盛り上げていきつつも、1つは上司の理解を得る手助けとして SEO の話を使うのはありかなと思います。
会社に対してパフォーマンスに取り組んだ結果を短期的に得たい人たちもいるので、そういった話をするのもありでしょう。
上司の理解が得られないのは、そもそも問題意識を持っていないと起きないケースが多いです。セキュリティは問題意識が高いほうが多いと思います。なぜなら、インシデントが起きるとそのあとの対応が非常に大変になるからです。
パフォーマンスに関しても、セキュリティのようなことが起きうると思っているので、しっかりと啓蒙していく必要があると思います。
例えばパフォーマンスが遅く、一気に負荷がかかって落ちてしまうと、同じくユーザーに対する対応を求められる時代だと思うので、そうした問題点をわかりやすく伝えられるようにしていくことも重要だと考えています。
potato4d:たしかにバックエンドの場合だと「パフォーマンス考えないのは信じられない」と考えますが、フロントエンドだと「ちょっとユーザー体験悪いかな」ぐらいになりがちですもんね。
古川:この質問は、テストをどこまで意識してやりますか?という問題と似ていますね。昔は「最初の方からテストはかかないでしょ」と言われていたと思います。しかし現在では割と啓蒙が進んで最初の方からテストを書くことが普通です。パフォーマンスもこの事例と同様で、本当は立ち上げ初期からパフォーマンスを意識していたほうがいいと思います。
理由は、パフォーマンスを下げるのは簡単ですが、上げるのは非常に難しいからです。本来は最初のほうからある程度パフォーマンスを考えて組み入れた状態で設計したほうが望ましいと思います。
ただ、もちろんサービスの立ち上げ初期という話からすれば、価値検証などの段階で、例えば 50ms にしなきゃいけないなど、そこまでを考えなければいけない訳ではありません。
あくまで、バランスの問題ですが、最初からパフォーマンスをある程度意識して設計しておくことをおすすめします。
そのためにも、開発者がやれることとしては、パフォーマンスを意識する余裕を持てるぐらいまで、自分の実力を上げていくことも重要です。
potato4d:エンジニアとしてはパフォーマンスを落とさないように、ひたすら技術を磨いていき、あとの調整は経営側がするという感じですね。
古川:やはり納期を間に合わせて、サービス立ち上げ初期の価値検証をやりつつも、パフォーマンスやメンテナンスアビリティをあげるというのはエンジニアの一つのスキルだと思うので、個人戦略としてはやったほうがいいと思います。
株式会社リクルート エンジニアリングマネージャー / ニジボックス デベロップメント室 室長
シニアソフトウェアエンジニア。Node.js 日本ユーザーグループ代表。Node.js evangelism WG/node.js collaborator/Chrome Advisory Board/TechFeed公認エキスパート


