ITエンジニアのキャリアに本気で向き合うメディア
ITエンジニアのキャリアに本気で向き合うメディア
目次
■信頼性と品質 / システム運用と管理
■リーダーシップとチームマネジメント

2022.10.18 2024.03.12 約4分
── 「つぎの一歩が見つかる、気づきと学びの場」 Forkwell Library シリーズ。第4回目は、2022年4月に出版され一躍人気書籍となった『システム運用アンチパターン』を取り上げます。
翻訳者の田中 裕一 氏による「権限がなくても明日から実行できる、アンチパターン解決アプローチ」を伺います。

田中 裕一(ギットハブ・ジャパン合同会社)
シニアソリューションズ エンジニア 東京工業大学情報理工学研究科修了後、サイボウズ株式会社を経て現職。現職では、セールス組織の中のエンジニアリングロールとして、さまざまな組織におけるGitHubの導入・活用を支援。過去には「Java最強リファレンス」(SBクリエイティブ)を執筆。今回「システム運用アンチパターン」にて初の技術書翻訳を手掛ける。
『システム運用アンチパターン』の原書は2020年10月に出版された『Operations Anti-Patterns, DevOps Solutions』です。タイトルにあるようにDevOpsのプラクティスを使い、どのように組織を良くしていくかをメイントピックとしています。
上層部はあまりDevOpsに興味がないけど、会社を良くしたい

こう考える現場エンジニアやチームリーダーの方に向けた内容が特徴的です。
11個のアンチパターンが具体的なストーリーを用いて紹介されています。本日は私の心に刺さった2つのトピックを紹介します。
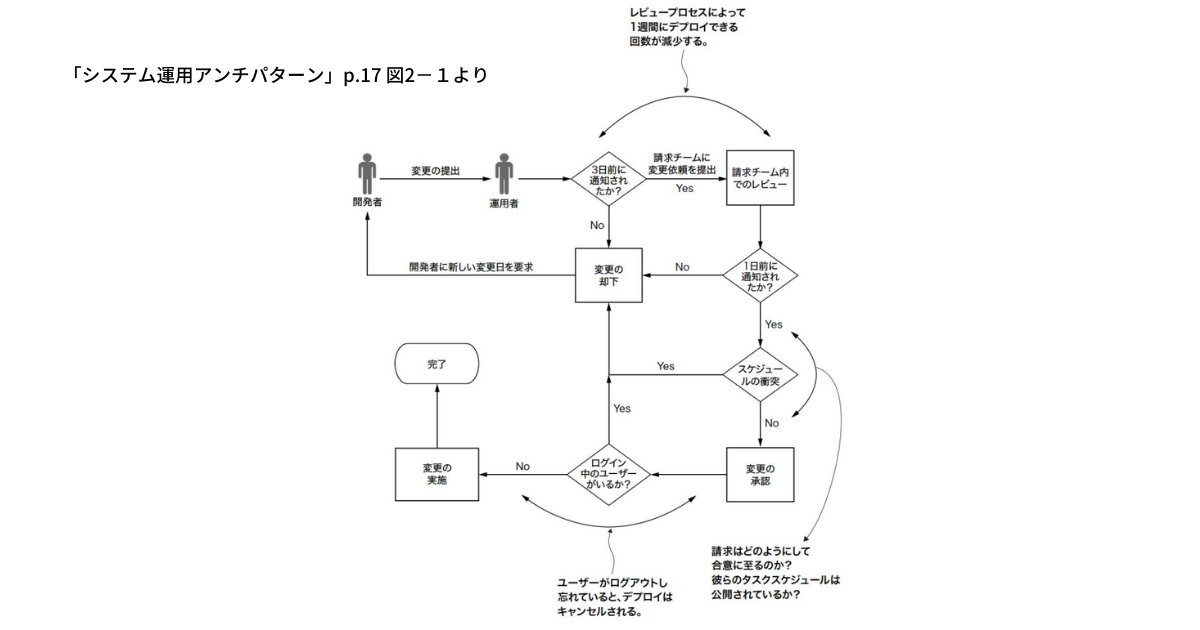
下記の事例をもとに考えてみましょう。
| “ある日、ステファニーが社内システムにデプロイをした。デプロイにはシステム再起動が必要だが、この時間にその社内システムを使っている人はいないとわかっていたので、問題ないはずだった。しかし、今回は急ぎの作業でそのシステムを使っている人がいた。デプロイの結果、その人の作業内容が失われてしまい、その人は作業をやり直す羽目になった。翌日、その人のマネジャーが憤慨し、再発防止を要求。その結果、この会社初の変更管理ポリシーが誕生した。” |
再発防止のために導入された変更管理ポリシーがこちらです。
| 1. 開発者は変更をデプロイするためのチケットを少なくとも3日前に提出。3日前までに通知されていない場合は1に戻る。
2. 利用部門によるスケジュールを確認。もしデプロイ予定日にその部門での作業が予定されている場合は1に戻る。 3. 運用部門による承認。デプロイの前日までに2まで完了している必要がある。完了していない場合は1に戻る。 4. デプロイの実行。ただし、その際にログインユーザーがいた場合はデプロイを中止し1に戻る。 |
「再発防止策を考えて」と指示されたら、このようなプロセスを策定しがちではないでしょうか。では、何が問題なのか見ていきましょう。
このプロセスを導入すると、デプロイ頻度が多くて週1回に制限されてしまいます。各ステップの3日前までに申請、前日までに承認、というフローがあるはずなので、どう頑張っても週1回が限度ですよね。各チーム間の余分なコミュニケーションが生じるわけです。
開発チームがシステム変更を加えたくても、実行するためには運用チームや利用者チームと調整が必要です。
実際には使っていないのに、ログインしっぱなしだった場合、デプロイが中止されてしまいます。せっかく1週間かけてここまで来たのに、1人がログインしっぱなしなだけで中止、やり直しになってしまう訳です。
どう考えてもこのプロセスは非常に重く、割に合わないですよね。これまで数多くの社内システムのデプロイは成功しているのに、たった1度の事故を解決するための反応としては明らかに過剰反応です。改めて「本来、達成したいことは何だったのか」を整理してみます。

達成したいこと = システムの安全性を高める(今回の場合、デプロイをしても利用者の作業が失われないこと)です。知らず知らずのうちに、利用者データを失うような作業が運用・開発チームで実行できてしまうことはシステムの安全性を損なう性質です。ここから脱却し安全性を高めることが、本来達成したいことです。
このような行動は大きな組織でよく見る光景ではないでしょうか。実は、これがパターナリスト症候群に陥る組織が取りがちな行動です。
| 親子関係のように、強い立場にある者が弱い立場の者に対して介入すること “パターナリスト症候群では仕事の進め方やタイミングをゲートキーパーと呼ばれる、権力を持つ人に委ねます。このような権力の集中は、最初は懸命な 判断のように見えますがすぐに生産性の低下を招きます。” (「システム運用アンチパターン」p. 9より) |
自動化で解決しましょう。『システム運用アンチパターン』は、自動化で改善できるポイントが4つあると提言しています。今回のような重いプロセスを自動化するときは、待ち時間と実行頻度が大事になってきます。
今回のケースの「待ち時間」は、開発者が申請を出してから実際に変更を反映できるまでの時間です。もし、これが人手によるプロセスならば承認者が夏休みなどの場合は、平気で1〜2週間かかってしまいます。待ち時間の自動化は、実行頻度にも影響します。現在の重いプロセスの場合、もし「細かい変更を頻繁にデプロイしたい」というニーズがあっても対応できません。自動化は重いプロセスを省略していく手段として考えると良いでしょう。
アンチパターンに嵌る組織に属している場合、解決策が自動化であることがわかっても自動化導入にあたってマネージャーや関係者を説得しなければならないという障壁が立ちはだかります。
そんなときに、現行のプロセスをこの4つの観点でまとめるわけです。
「今のプロセスだと、待ち時間がこのぐらいかかってます」「実行時間が長すぎます」といったように打ち出します。まず現状に問題があることをマネージャーに理解させましょう。
元々自動化に積極的ではない組織に属している場合、簡単なスクリプトで自動化を再現してみせても、説得材料としては少し弱いかも知れません。下記の4点を考慮すると良いでしょう。
| 【筆者のおすすめ】もし社内にJiraのようなイシュー管理ツールがあれば、そこにチケットをあげることが申請になります。申請をトリガーにして自動化スクリプト実行し、結果ログもそのチケット中に全て集約します。社内のチケットシステムは既に社内プロセスに折り込まれているものなので監査もしやすいメリットがあります。 |
| 【Point】自動化によって自動化以前の承認者の仕事が奪われてしまう側面を考慮しましょう。少し根回し要素になりますが、自動化前に承認フローに組み込まれていた人物をきちんと自動化に巻き込むことも重要です。 |
これは被害にあっている方も多いのではないでしょうか。下記の事例をもとに考えてみましょう。
| “レイモンドがオンコール担当していた日の午前4時、データベースのCPU使用率が95%になっているというアラートで起こされた。調査を開始したが、システムのアクティビティは正常。データベースのログにエラーも出ていない。1時間ほど寝ずに調査を続けても、おかしな所は見つからない。そのうちにデータベースのCPU使用率も正常に戻っていった。しかし、その次の日も同じアラートで夜中に起こされることになる。” |
先ほどの事例では、データベースのCPU使用率が95%というアラートが飛びました。しかし、誰にどのような影響を与えるか、直すために何をしたらいいのか、何もわからない状態であり、これは行動可能な状態ではありません。システムメトリクスのみに基づいたアラートは基本的に行動可能でない場合が多く、アンチパターンに陥りがちです。
01 行動可能である
02 タイムリーである
03 適切に優先順位づけされている
|
システムメトリクスのみでは、あまりうまくいきません。そこでカスタムメトリクスがおすすめです。カスタムメトリクスとは、ユーザー/ビジネスの観点でシステムが正常に動作しているかどうかを知るためのメトリクスです。
カスタムメトリクスの設計には、ユーザーやビジネスの観点が必要となるため、運用チームだけではなく、開発やプロダクトチームを巻き込んでいきましょう。
| 故障モード影響分析 エラーが発生する可能性のある箇所を洗い出し、以下の軸を1〜10でスコアづけ – 深刻度 (1:深刻でない 〜 10:深刻) – 発生頻度 (1:ほぼ発生しない〜 10:頻繁に発生する) – 検出可能性 (1:検出が容易 〜 10:検出不可能) これら3つのスコアを掛け合わせて値が高いものから優先 |
ユーザー観点、ビジネス観点で「うまく動いてるかな」「何か異常が起きてないかな」という質問に答えるために、取得したいメトリクスの候補はたくさんありますよね。膨大な候補をどう優先度付けすべきなのでしょうか。『システム運用アンチパターン』では故障モード影響分析の使用を例にあげています。まずチーム全体で候補を洗い出し、そこに深刻度、発生頻度、検出可能性の3つの観点でスコア付けをしていきます。要は深刻で頻繁に発生し検出が難しいものが最優先です。対処方法も3つに分類できます。「深刻度をさげる」「発生頻度をさげる」「簡単に検出できるようにする」いずれかの改善策を実施しスコアの再評価をしても、まだ高得点の場合は再度改善の必要がありますし、スコアに変動があれば別のタスクを最優先で対応していく方法です。
アラートの改善を上層部に提案する場合、下記を計測すると良いでしょう。
|
本日は11あるアンチパターンから2つを紹介しました。『システム運用アンチパターン』で紹介されているストーリーは非常に “あるある” な内容なので、社内勉強会などで共感を高めるときにも活用できそうです。ぜひ詳しく知りたい方は書籍に目を通してみてください。
30分でわかるシステム運用アンチパターン / Operations Anti Patterns in 30 minutes
シニアソリューションズ エンジニア
東京工業大学情報理工学研究科修了後、サイボウズ株式会社を経て現職。現職では、セールス組織の中のエンジニアリングロールとして、さまざまな組織におけるGitHubの導入・活用を支援。過去には「Java最強リファレンス」(SBクリエイティブ)を執筆。今回「システム運用アンチパターン」にて初の技術書翻訳を手掛ける。


