ITエンジニアのキャリアに本気で向き合うメディア
ITエンジニアのキャリアに本気で向き合うメディア
目次
■クラウド&インフラストラクチャ

2022.05.08 2023.12.14 約5分
Forkwell が主催する技術イベント「Infra Study」。今回は「VM時代の開発とCloud Native時代の開発」というテーマで開催しました(開催日:2020年 5月20日)。第3部では、青山さんの基調講演内容から、Kubernetes による Cloud Native 開発のこれからを紹介します。Q&A ではまつもとりーさんを交えて、視聴者さんの質問にお答えしています。この機会にクラウド化に取り組もうとするインフラエンジニアからの質問もあります。ぜひ参考にしてください。
ここからは将来の話をするために Kubernetes の話を深掘りします。

Kubernetes はあるべき理想の状態へ収束する仕組みを持っています。例えばこの図のような ReplicaSet 定義を入れると、その状態へ収束してくれます。何か問題が生じたときも、Kubernetesの中ではController というプログラムが中で動いていて、セルフヒーリングしてくれます。
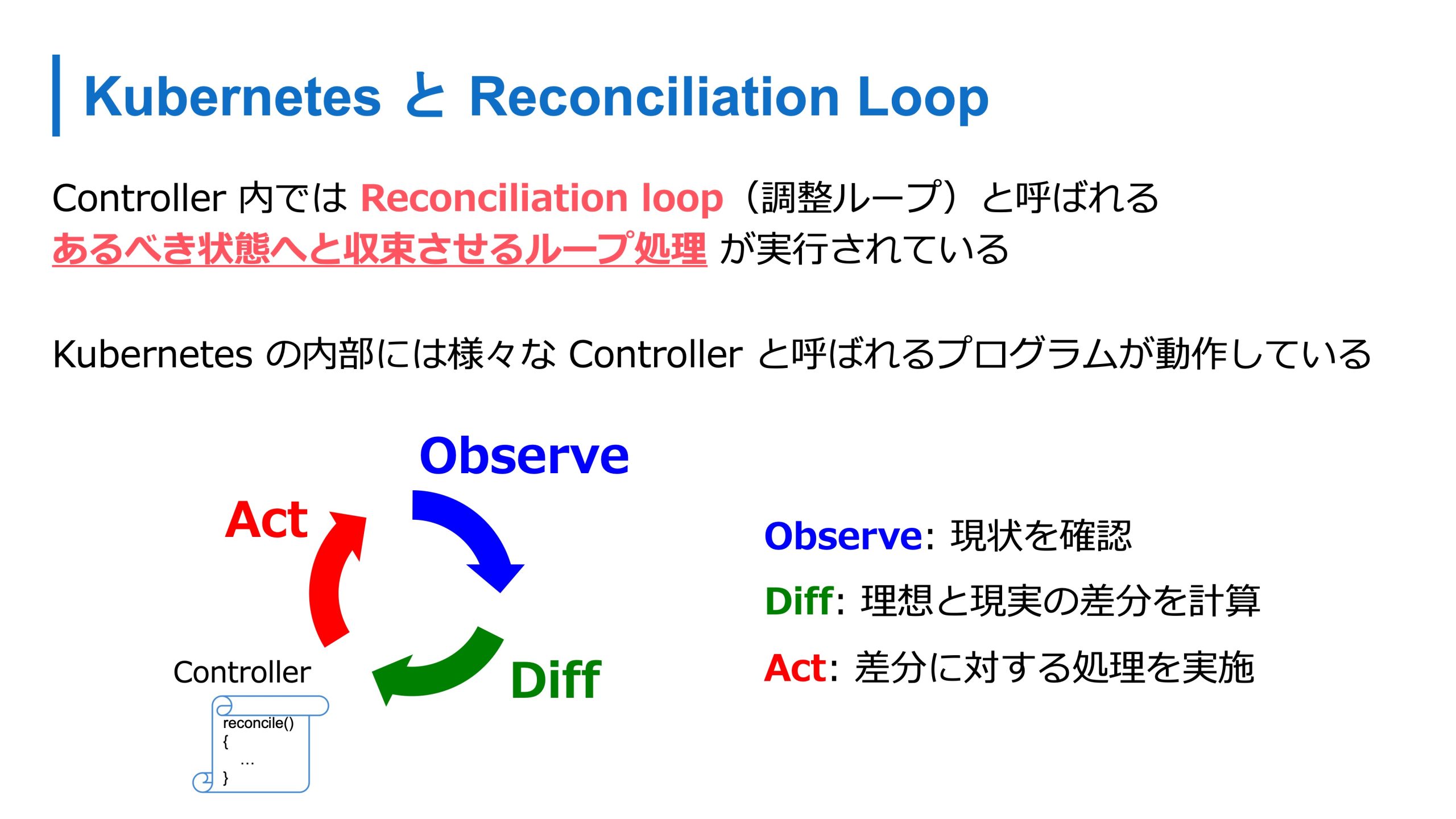
Controller の内部では、Reconciliation loop(調整ループ)と呼ばれるループ処理が動いていて、これによってあるべき状態に収束しています。Reconciliation loopでは、現状を確認し、差分を確認計算して、差分に対して何かしらの処理をするようなループ処理です。

この Controller は Kubernetes の中で様々なものが動いています。たとえば ReplicaSet 向けには ReplicaSet Controller がいます。ReplicaSet Controller の責務は指定したレプリカ数で Pod を維持し続けることです。

例えば、コンテナを3つ起動させるという定義で2つしか起動していない場合は、1個足りないねと検知し、 Controller が1個追加してくれます。
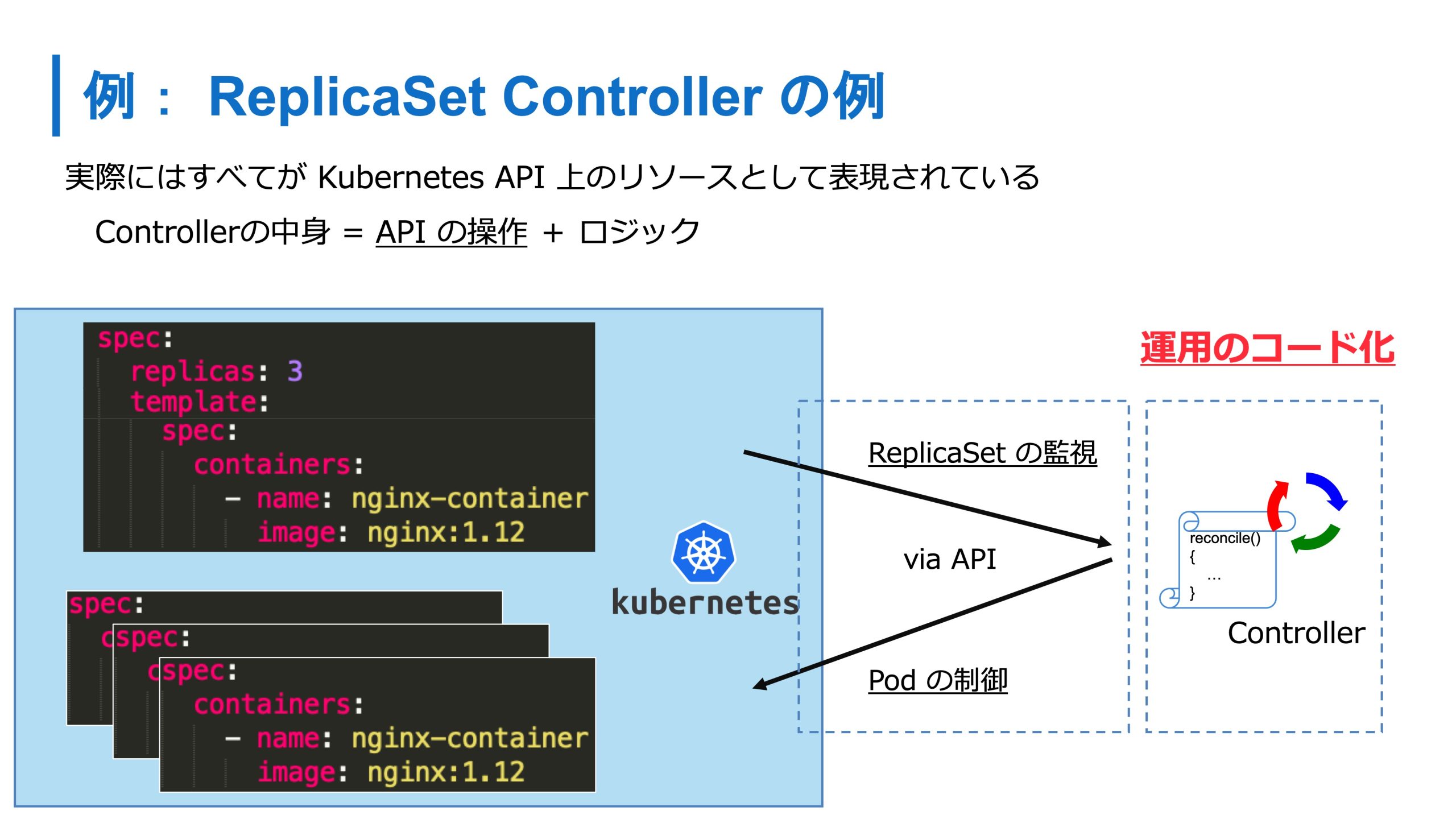
この操作は、Kubernetes の API と Controller 間の API 通信によっておこなわれてます。Kubernetes の API 経由で Pod の情報が変更されたのを検知すると、Controller 内のロジック、つまり運用のロジックによって自動的に処理がおこなわれます。
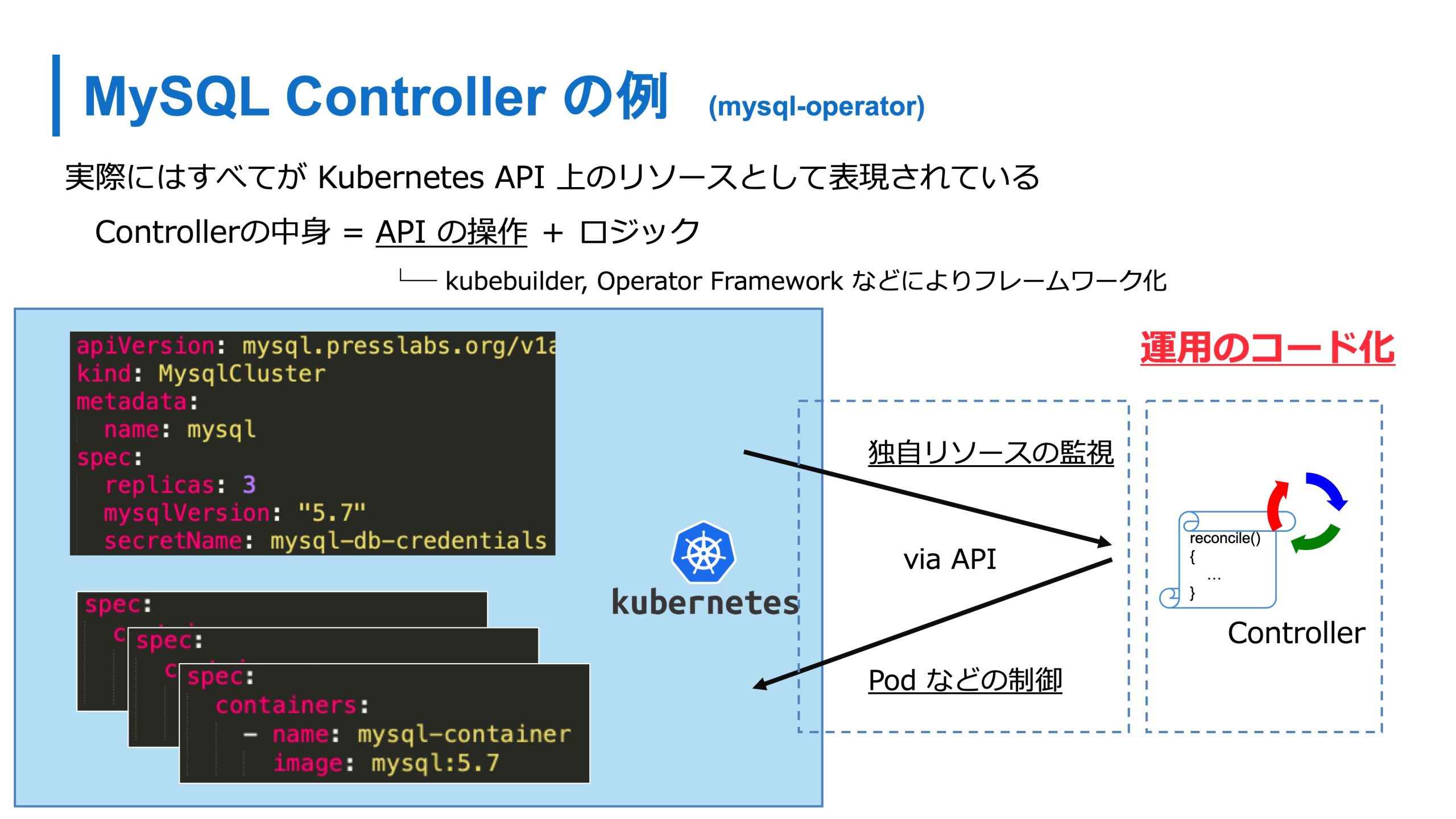
たとえば MySQL のカスタムリソースを作ったときには、それを監視しつつ、Controller がそれを運用します。MySQL のクラスタが壊れたら直すみたいなロジックを入れておくことで運用のコード化、運用ナレッジをプログラマブルにすることができます。
このように Kubernetes では Controller を使い、運用ロジックや運用ナレッジを自動化していくことができます。
この機能を使い、いずれはすべてが Kubernetes YAML になるんじゃないかなと考えています。ここら辺が Orchestrator として Kubernetes に未来を感じている部分です。

いくつか自動化のパターンがあると思いますが、1つ目は、一般的な運用自動化系のロジックです。たとえば、社内に伝わる秘伝のスクリプトみたいなものは、汎用的に Controller 化されます。
これらはオープンソースのエコシステムの Kubernetes の拡張機能として広く共有されて、誰でも使えるようになります。みんながそれを使うことにより、点在していたような知識が、キレイに1つに集約されて、誰でも使えるようになっていくと考えています。
たとえば、特定のリポジトリにあるマニフェストを Kubernetes に apply するような運用だったり、ロードバランサのIPアドレスをDNSに登録するとか、証明書を発行してSecretとして登録するとか、コンテナのリソースの使用率から自動的にリソースの割り当てを変えたりとか、こういったものはすべて運用上やっていたようなものが Controller として実装されて、今 Kubernetes 上で使えるものたちです。

2つ目は、詳細は紹介しませんが、ステートフルなミドルウェアを運用するための Controller を作るパターンです。俗にいうオペレーターです。
さっき紹介した MySQL Cluster のリソースを作ると、自動的に Pod が作られて MySQL クラスタを作って運用をしてくれるような世界観もいつか来るかなと思います。
データベースに関しては、Pod のライフサイクル的に適用するのが難しいのと、クラスタ間でデータベースを移行したいときにちょっとつらいので、そこそこ先になるかな?と思いますが、Message Queue や KVS は、少しステートを持っている Computing リソースの延長線上ぐらいにあるコンポーネントと捉えることができるので、近いうちに現実的になるかなと思います。
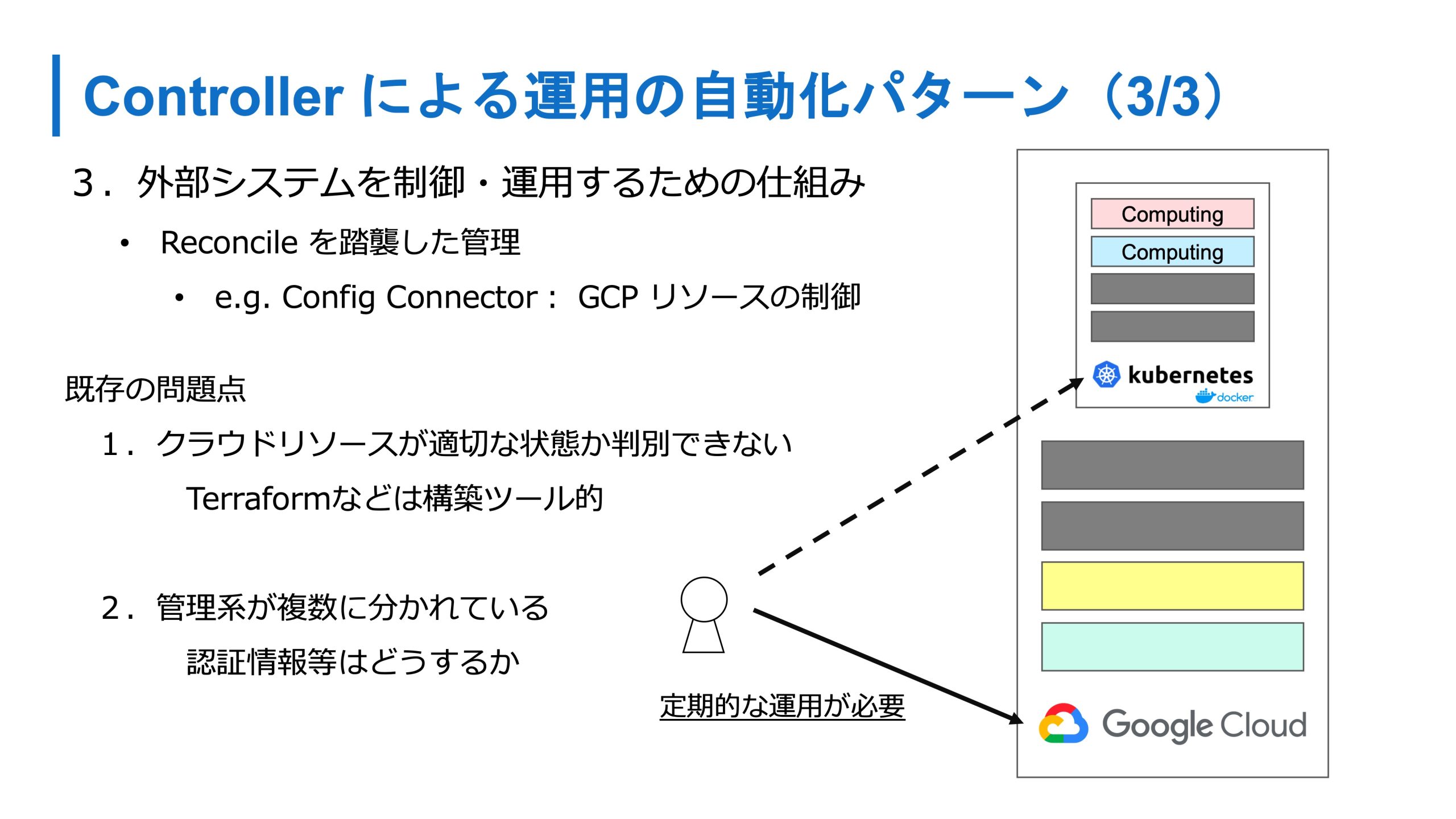
3つ目が外部のシステムの制御運用をするための仕組みです。さっきクラウドとうまく連携しましょうという話をしましたが、クラウド上のリソースを扱うときはよく Terraform を使います。
Terraform の問題点でもないんですけれど、実行していないときに適切な状態かどうか判別できなかったりします。
あとは Kubernetes と Terraform の両方を管理する必要や、そのデータベースに対する認証情報とかも、Kubernetes に伝える必要があります。
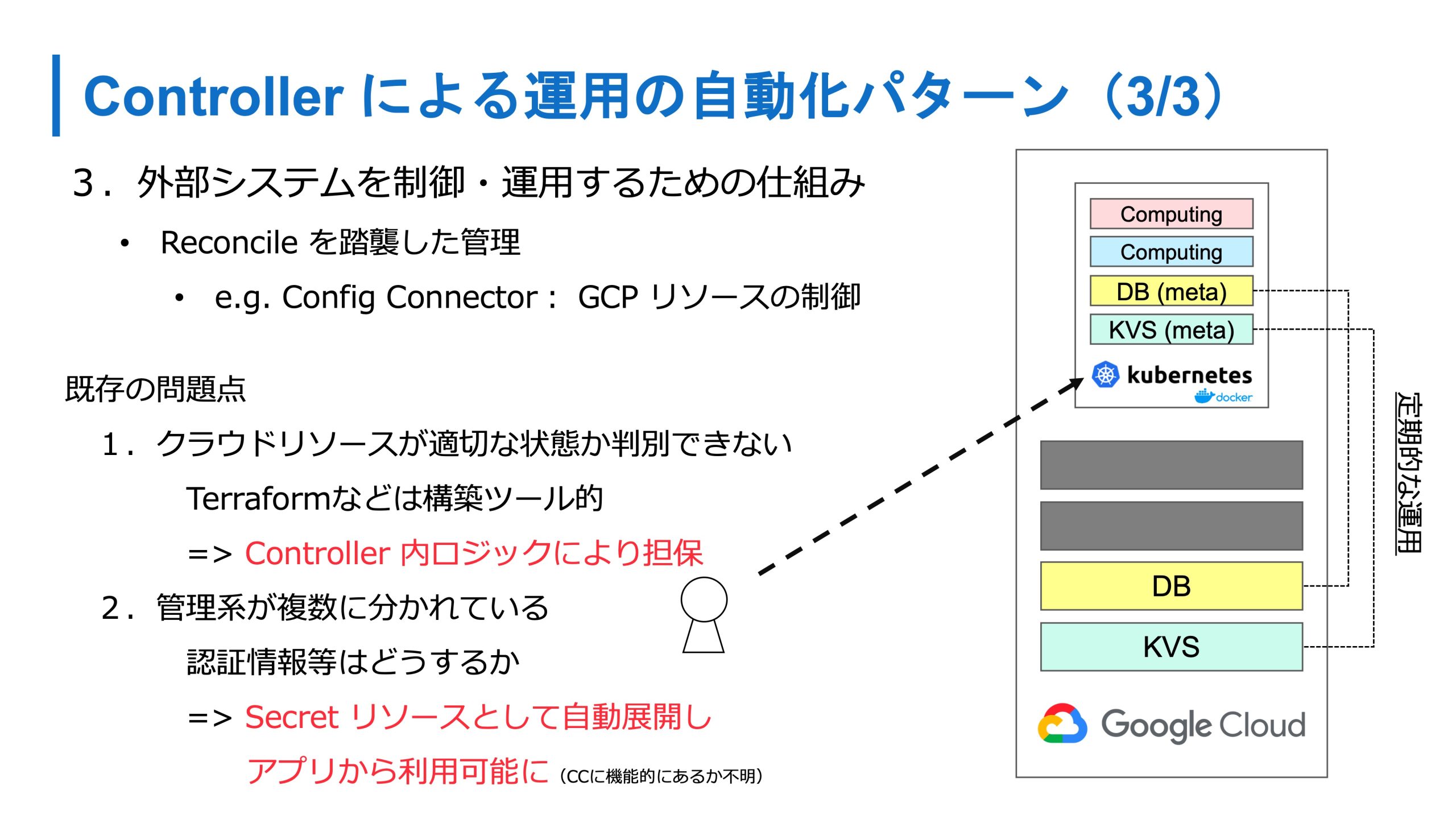
最近 GCP では Config Connector が出てきてますが、本コネクタでは DBリソースというメタ的なリソースを作ると、Kubernetes の Config Connector の Controller が、実際に GCP のデータベースを作ったり、その状態に維持ところに責務を持って運用をしてくれます。
かつ、Config Connector でこの機能があるかはわかりませんが、この機能を持つパターンの実装だと、データベースを作ったあとに、そのデータベースの認証情報などを Secret として同期する機能もあるので、管理系統を Kubernetes に集約できます。全部を Kubernetes に載せるのではなく、実態はクラウド上にいるといった共存のパターンもあります。

今回のスコープだと Kubernetes 以外のコードでは、 Dockerfile や Terraform のコードとかも残ると思いますが、 Dockerfileに関してはCloud Native Build Pack とかで、Dockerfile 自体が不要になったり、ソースコードだけでいい世界観が来るかもしれません。Terraform とかもクラスタの初期構築やアドレスの管理ぐらいだけにすることもできます。

クラスタ運用の自動化により、クラスタ自体はマネージドサービスに完全に任せられるような世界観も、結構来ていると思います。初期構築自体も Terraform じゃなくて、手動でワンポチやるだけでも良くなるかもしれません。

冒頭・前半でお伝えしたのは、Cloud Native は、アプリケーションの実行を第1に考えたときに、どういうインフラを作るかに立ち返り、再定義して作られた考え方ともいえます。
VM時代と比較すると、安定して即座にビルドからデプロイまでを実現できますし、アプリケーションの運用をベストプラクティスとして、コード化や抽象化されていたり、 Dev と Ops の距離は非常に近づいていると思います。
将来性の話でいうと、Kubernetes は、さっきの Controller の仕組み、Reconciliation Loop で運用の自動化をおこないます。運用の自動化をおこなうエコシステムはたくさん出てきているので、こういったものを積極的に利用して、我々は開発をよりよく、楽にしていけそうですね。

最後にせっかくなので5年後(2025年)の一般的なインフラの環境を予測します。
オンプレだと、データベース以外は Kubernetes 上で動作しているかなと。パブリックに関しては、さっきのクラウドリソースを操作するようなものを使い、全部 Kubernetes で管理されているようなことも割と一般的になると思います。
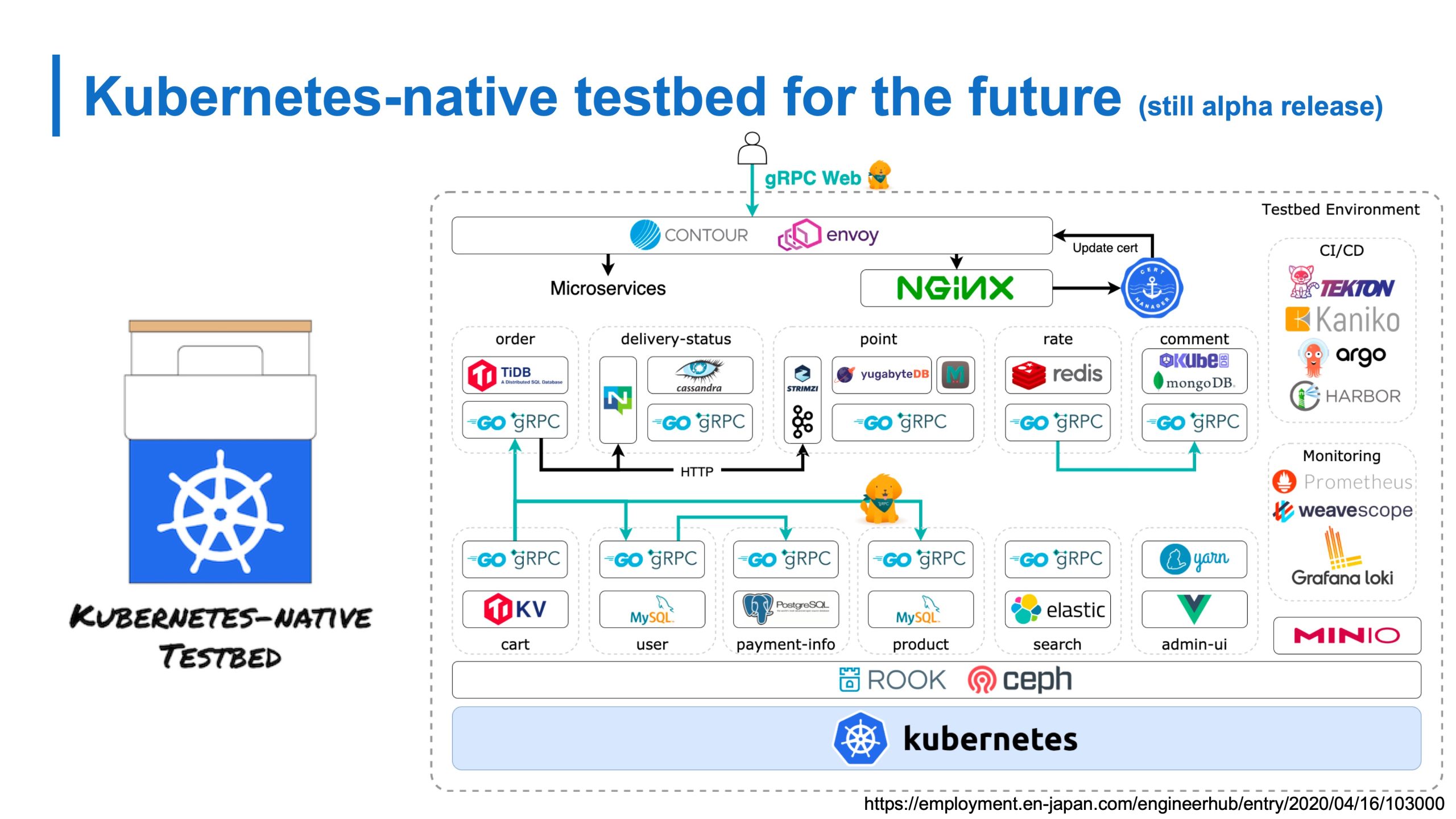
一応オンプレ上でさまざまな Controller を使った Kubernetes による管理を検証するためにKubenetes-native testbed を OSS として公開してます。サイバーエージェントの同僚の漆田くんと一緒に2人で作っています。もし興味があれば見てほしいです。すごい遠い未来じゃないような、今使われているような技術もここで使ってたりするので、そういった設定例とかを真似てみて欲しいです。またすべてが Kubernetes-native になるんじゃないかなと思います。
ご清聴ありがとうございました。
青山:今ある Cloud Native な Kubernetes とかクラウドを使ったインフラエンジニアになりたいのであれば、今だともう Kubernetes に関していえばミドルウェアを動かそうとしたときに、マニフェストが公開されているので、正直1コマンドで、そのコンポーネントを動かすことができます。
クラウドを使ったインフラエンジニアになりたいのであれば、色々なコンポーネントや新しく出てきたものを動かしてみる。どのような経緯や設計思想で作られたのかを見ていくのがいいのでは?
特に盛り上がってるようなコンポーネント、プロダクトは何か理由があって作られてることも多いですし、またそれを発表している資料もあるので、どういう経緯で作られたかを、うまいことを抜き出していくと、肌感覚がつかめていくんじゃないかなと思います。
まつもとりー:便利になってワンボタンでできるようにはなったものの、実際それがどういうふうにできてるのかを見ながらやっていくと、いざというとき、自分自身も同じような思想に基づいて作れるようになる可能性があるんですね。
青山:マネージドじゃないときに、運用をしたくないなと思うときはあります(笑)私はツラくても楽しいですけど、他の人におすすめしづらいですし、多分それが一番ツラいと思います。
2つ目は自分自身がいいと思ったエコシステムを入れたときに、もっといいものが出てきた場合、入れ替える必要が出てくるんですよね。
入れ替えないと負債になるので、その基盤側の Cloud Native な思想というか、入れたらおしまいではなくて、下回りも適宜変えていくっていう気持ちを持ち続けるのはツラいかもしれないですね。
まつもとりー:Kubernetes 自体もどんどん変化していく、Cloud Native していくということですよね。
青山:Kubernetes よりかはエコシステム周りですかね。Kubernetes を前提としたプロダクトって感じですね。Argo CD が別のものに置き換わった、もっといいものができたとかを楽しめるようにしたほうがいいと思います。
まつもとりー:環境が変わっていかないことを前提にすると結構変化がきつくなる感じはわかるんですけど、逆にそういうものなんだと理解して、それをやることを当たり前にしつつ、そこを楽しめば、結構やれるもんだという感じですかね。
青山:そうですね。今普通にクラウドを使っているようなWeb系の企業なら大丈夫かなと思います。
まつもとりー:エコシステムも含めて結構変化が激しいけど、そういうものだと理解する必要がある。でも現状はギャップがあって疲れるしツラいのかもしれませんね。
青山:アプリケーションを開発するうえで適切なインフラの基盤は何だろうと考えたときに、今回だとBeanstalk でいいのか?という問いに、関係してくるかなと思います。
たとえば Beanstalk を使ってもいいと思うんですけど、Beanstalk だとあんまりインフラ層や開発者から触れなかったりします。
あとはさっきの Kubernetes の話に関していうと運用の自動化系のコンポーネント、エコシステムがいっぱい拡充していますが、Beanstalk だとKubernetes に比べると圧倒的に少ないと思うんですね。
自前で作る部分が多すぎるとか、開発者から制御できない、できなさすぎみたいになったときに Kubernetes を入れたほうが解消できるので、導入したほうがいいっていう判断になるかなと思います。
まつもとりー:開発者目線から、いわゆる今までインフラと呼んでいた領域をコントロールできるのか。そういう視点が大事ですね。ちなみに今いっている Kubernetes とは、マネージドの Kubernetes ですか?
青山:Beanstalk と比べるのであれば、マネージドと比べないとちょっときついと思います。もしくはスペシャルなインフラエンジニアがいっぱいいる前提とかですかね。
青山:個人個人によってバラバラだとは思うんですけど、私としては、まず開発者は少なくとも、Dockerfile を作り、コンテナイメージを作るところまでは、やるべきかなと思います。
手元で docker buildしてちゃんと通る、ちゃんと手元で動くアプリケーションが動くところまで確認してから、Dockerfile ごと、アプリケーションを GitHub に上げると。そしたら実際に自動的にイメージが作られるところまではフローとしては分けたほうがいいと思います。
問題は Kubernetes のマニフェストのほうですね。インフラ層をどこまで触らせるのかみたいなところに関しては、マニフェストのファイルは基本的に全部 GitHub にコードとして置かれるようになるので、変更する場合は直接 Kubernetes に対して、CLI から操作するんではなく、基本的にはリポジトリの更新になると思います。
ここは正直お互いがやるべきかなと思います。当然得意不得意があり、ストレージ系の操作やネットワーク系の操作とか、あとはポリシー系の操作とかは、インフラエンジニア相当の人がやっていることが多くなるでしょうし、もうちょっとアプリケーション的、内部のロードバランサみたいな機能のところは開発者側がやったほうが、すぐ済むと思います。
なのでそこら辺は一緒にやるのがいいと思います。PR もレビューも相互にやれば、その構成がわかるようになるので、メリットがあるかなと思います。お互いが把握していられるところが分解点かなと。
まつもとりー:青山さんの経験的に責任分界点を決める難しさ、実際に生じた問題はありますか?
青山:割と自分がインフラサイドっぽいことを仕事にしてるのもあるんですけれども、そんなに Web系の企業で、このマニフェストの管理でもめるみたいなことは聞かないですね。
言葉を選ぶならばレジェンド企業みたいなところでは、境目がすでにある。Dev と Ops の境目がすごいみたいなところだと、そもそも Cloud Native にいくよりも、もうちょっと前段のところかなと思います。
あくまでも、Cloud Native はクラウドの延長なので、クラウド後期ぐらいにまだ馴染めてないんじゃないかなと思いますね。
まつもとりー:まず使うことよりも組織的な問題とかもあると思うんですけど、その辺何が問題かをもう一度再確認してから、青山さんの本とスライドを参考にしつつも、一歩ずつその間を埋めていく作業がいるんじゃないかということですね。
青山:そうですね。いわゆるクラウド前期ぐらいのところから一気に Cloud Native をやろうとすると、かなりの軋轢を生むような気はしてます。
まつもとりー:分業が割とちゃんとなされたところにいきなりこのソフトだけを入れて、ソフトでの運用を一緒にやるみたいな感じになると、ギャップは簡単に埋まらないし、変になりそうですね。
Infra Study 運営の赤川です。このイベントは1,700名以上の方から申し込みがある大注目イベントとなりました。青山さんの講演の他にも、5人のインフラエンジニアの方々に、LT登壇をしていただいています。
また、発表者同士によるアフタートークでは、「Kubernetes を導入する際に、アプリ側のエンジニアとインフラ側のエンジニアでどのように協業し、どのように境界を設定するのか」といった話題について、登壇者それぞれの立場の意見を聞くことができ、見応えがあります。

客員研究員
#Kubernetes 完全ガイド 著者、#CNDT2019 #CNDT2021 Co-chair、#cloudnativejp #k8sjp #KubeConJP Organizer、さくらインターネット研究所 客員研究員、CREATIONLINE 技術アドバイザ、3-shake 技術顧問、PLAID




