ITエンジニアのキャリアに本気で向き合うメディア
ITエンジニアのキャリアに本気で向き合うメディア
目次
■信頼性と品質 / システム運用と管理

2023.08.14 2024.03.05 約4分
| この記事は、2023年7月11日発売 『SLO サービスレベル目標―SLI、SLO、エラーバジェット導入の実践ガイド』翻訳・監修者の山口 氏による connpass勉強会 を再編集し、記事化したものです。 |
タイミー社による事例講演はこちらからご覧ください
| 「信頼性」を追求する新たな方法論として、Googleの副社長、Ben Treynor Slossが2003年に提唱したSRE(Site Reliability Engineering)は、開発と運用の両面における革新的なアプローチです。その理念は、2016年に出版された「Site Reliability Engineering: How Google Runs Production Systems」によって広く認識され、Amazon、Facebook、Airbnb、Dropbox、IBM、LinkedIn、Netflix、Wikimediaなど、世界的なテクノロジー企業がSREを採用し、もはやニューノーマルになっています。
SREを採用していない開発部署が必ずしも時代遅れとは言えませんが、SREの手法を取り入れることで、システム全体の信頼性とスケーラビリティをより効果的に管理できることは確かです。そして、開発チームだけでなく、組織全体がSREの理念を理解し採用することで、高い信頼性とユーザー満足度を実現するサービス提供の「道標」を得ることができます。 |
信頼性の高いサービスは、顧客の満足度を向上させ、企業の評判やブランドイメージを築く重要な要素です。どれだけリリースをしても、顧客満足度、つまり信頼性の低いサービスでは意味がありません。サービスの信頼性は特定の部署のみが意識するものではなく、会社全体で意識・共通理解すべき指標なのです。
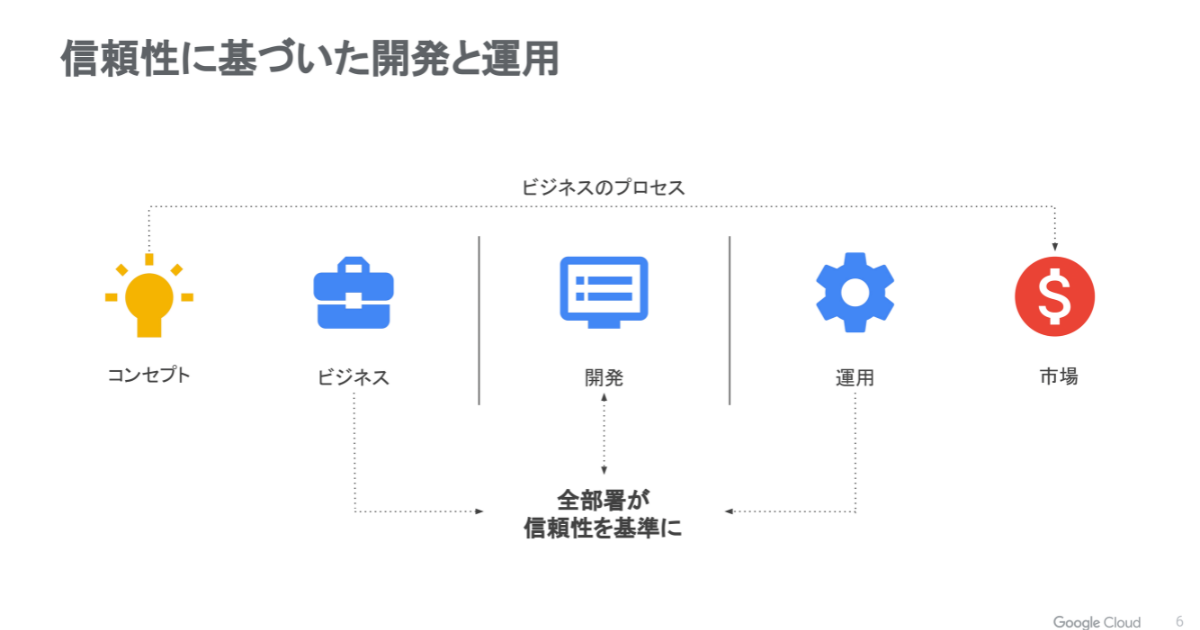
信頼性の定義を見てみましょう。
| システムが求められる機能を、定められた条件の下で、定められた期間にわたり、障害を起こす ことなく実行する確率 |
つまり、サービスやシステムに求められる機能が実行される確率を計測できれば良さそうです。

指標(SLI)を設定します。指標(SLI)は、ユーザーから求められる機能、ユーザー満足度に相関する指標でなくてはなりません。ユーザーから求められる機能は、サービスの性質によって異なるため、適切に見極めることが必要です。
下記に指標の一例を出してみました。
サービスの性質による典型的な信頼性指標の元データ
|
この指標はあくまで典型例のため、当てはまらないケースもたくさんあります。例えば、CPU・メモリの使用率などのメトリクスを、ユーザー満足度に相関があると思い込み指標にしてしまうパターンです。ユーザー視点で考えると、自分が使ってるブラウザの向こう側にあるサーバーのCPUの使用率がいくら高かろうと関係ないはずです。自分が期待している時間内に期待されたレスポンスが返ってくれば問題ありませんよね。

指標(SLI)は、ユーザー満足度に相関するか?を見極めよう
求められる機能を洗い出せたら、次は実行確率を計算しましょう。SLIは、以下の式のように定量的かつ慎重に定義します。

冒頭で話したように、サービスの信頼性は特定の部署のみが意識するものではなく、会社全体で共通理解すべき指標です。技術的な知識のない人にも「だいたいこんなことをやっているんだな」と理解してもらうために、言語化しましょう。
| SLI の種類:可用性
SLI の仕様:CheckoutService へのリクエストに対するすべてのレスポンスのうち、HTTP レスポンスコード 2xx、3xx、4xx を返すもの (=良いレスポンス) の割合。 ただし 429 を除く。 SLI の実装:Web アクセスログから HTTP レスポンスコードを特定する |
言語化ができたら次はサービスレベル目標(SLO)を設定します。SLOを設定するために、計測期間・確率の目標値を定義しましょう。
| ● SLI: CheckoutService の良いレスポンスの割合
● SLO:CheckoutService の過去28日間の良いレスポンスが99.9% |
SLIと同様に、SLOも言語化しておきましょう。
| SLI の種類 : 可用性
SLI の仕様 : CheckoutService へのリクエストに対するすべてのレスポンスのうち、HTTP レスポンスコード 2xx、3xx、4xx を返すもの (=良いレスポンス) の割合。ただし 429 を除く。 SLI の実装 : Web ログから HTTP レスポンスコードを特定する SLO : 過去 28 日間の CheckoutService のレスポンスのうち 99.9% が良いレスポンスでなければならない 根拠 : 過去に0.1%までのエラーであれば顧客問い合わせがなかった |
このドキュメントがあれば「いま使っている指標は、本当にユーザーの満足度に相関してるの?」という定期的な議論に役立ちます。
SLI・SLOを設定し、エラーバジェットを算出することで、リソースを効率的に配分できます。SLOは、その値を満たしてれば、ユーザーが満足できるという値ともいえます。つまり、その値までは、故意に障害を発生させたとしても、ユーザーは使い続けてくれると仮定できるわけです。先ほどのSLI・SLOの例では、このように設定しました。
| ● SLI: CheckoutService の良いレスポンスの割合
● SLO:CheckoutService の過去28日間の良いレスポンスが99.9% |
可用性が99.9%。つまり 0.1%分のエラーは、ユーザーが許容できる範囲ということになるので、「だったらそのエラー分をさまざまなチャレンジのための予算にしよう」と考えることができます。
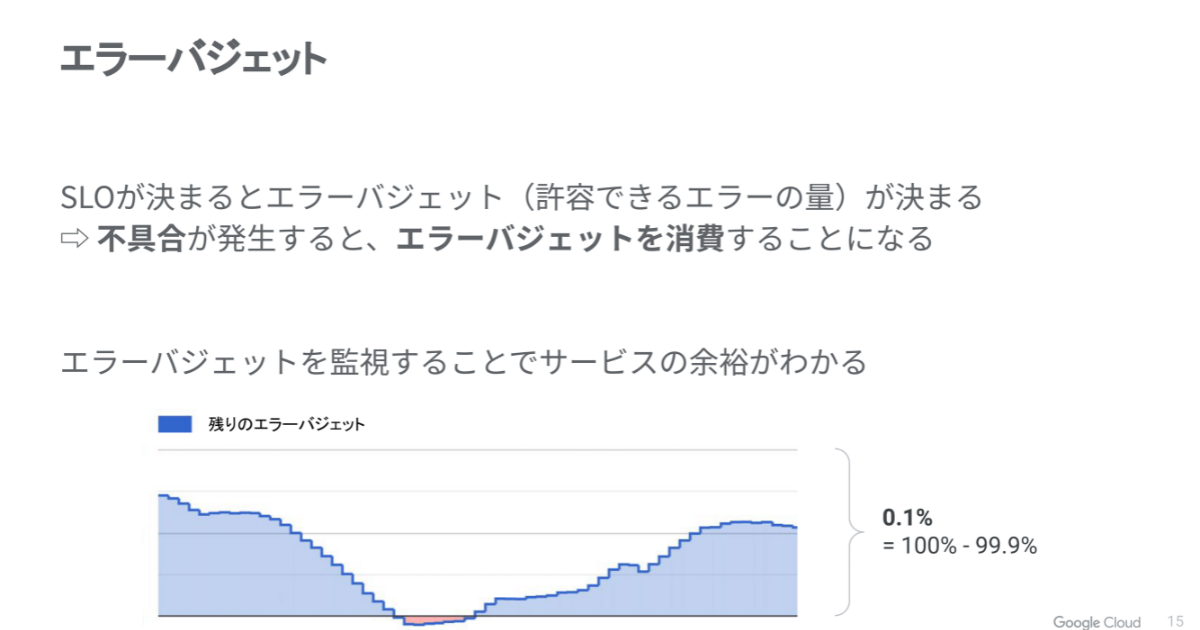
エラーバジェットを監視することで、システムの運用にどれくらいの余裕があるかが一目瞭然になってきます。
さらにもう一歩進んで考えていきます。エラーバジェットは、ユーザーが不満足になるまでの余裕分です。その消費速度を追いかけることで、現在置かれた状況を判断できます。
先程の例で考えてみましょう。
| ● SLI: CheckoutService の良いレスポンスの割合
● SLO:CheckoutService の過去28日間の良いレスポンスが99.9% |
可用性の目標が 過去28日間 の良いレスポンスが99.9%ということは、28日間で 0.1%のエラーを起こす想定です。これがバーンレート1の基準になります。14日間 で 0.1% のエラーが起きると、バーンレート2となります。この基準を使えば業務の優先順位や緊急度を適切に判断することができます。
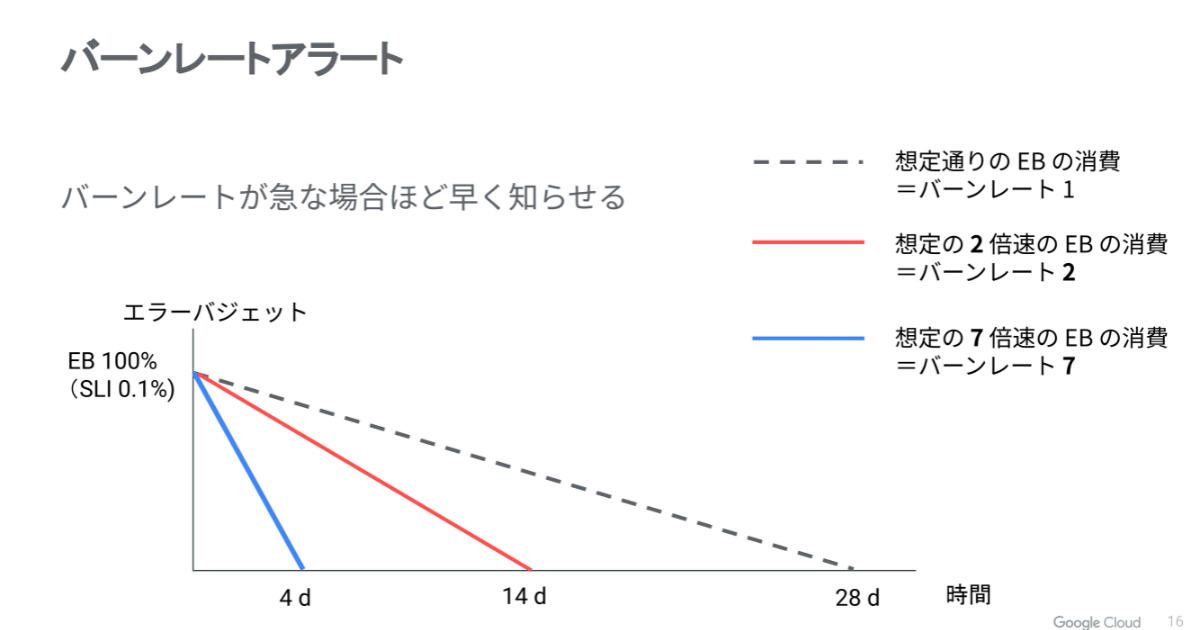
さらにエラーバジェットを使って、ポリシーを定義することもできます。エラーバジェットのレベルに応じてポリシーを決めておくと、組織全体が緊急対応しやすくなるなどのメリットがあります。

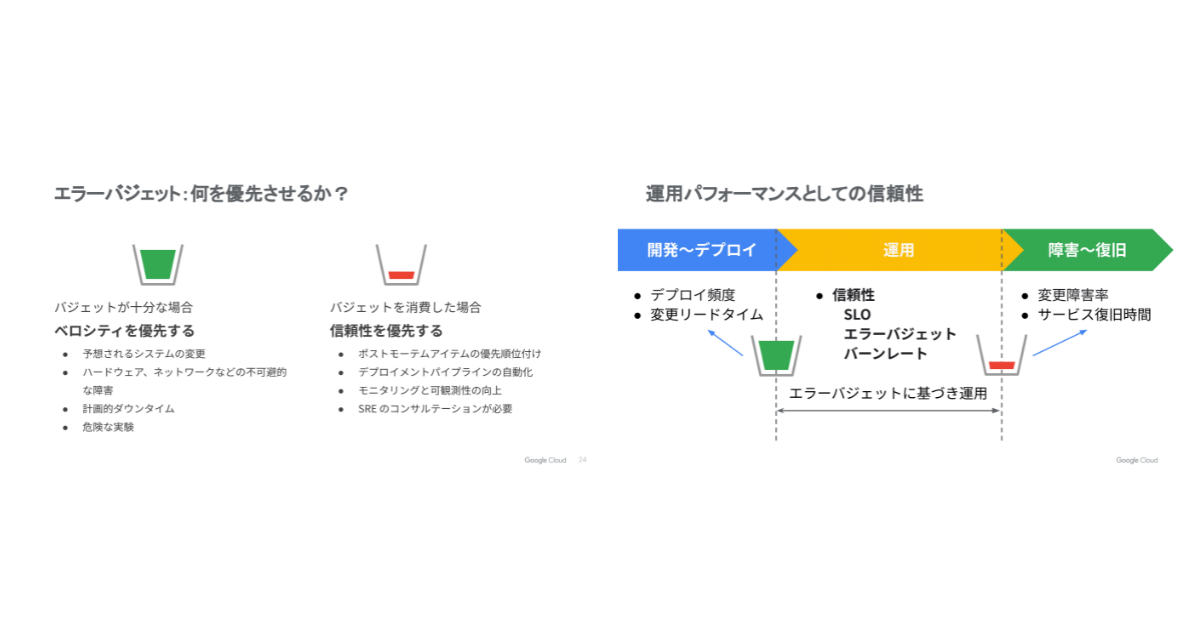
Four Keys は、2017年発売の書籍『LeanとDevOpsの科学』で提唱された開発生産性を示す4つの指標(デプロイ頻度・変更リードタイム・変更障害率・サービス復旧時間)です。この4つの指標は、あくまでソフトウェアデリバリーに関係する指標であり、安定時のパフォーマンス(ユーザー満足度)が欠けています。
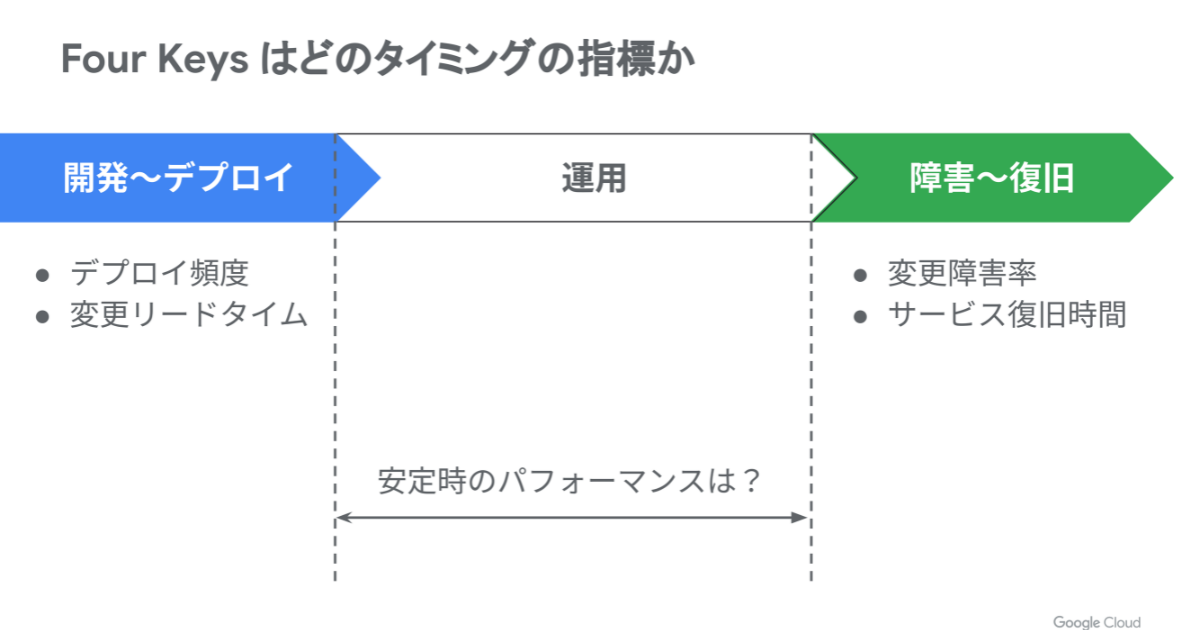
しかしシステムというのは、ユーザーの信頼性がなければ意味がありません。そこで「組織のパフォーマンス」が再考され、State of DevOps Report (SODR) 2018以降では新たに信頼性(可用性)に関する記載が加わりました。
|
2018年以降は「信頼性」を指標として計測することが推奨されています。信頼性を優先することで、従来のエラーバジェットの考え方も図のように変化しています。
SRE サイトリライアビリティエンジニアリング―Googleの信頼性を支えるエンジニアリングチーム
SLO サービスレベル目標―SLI、SLO、エラーバジェット導入の実践ガイド
山口:SLOのユーザーの中には、人間だけでなく、APIを投げるすべてのサービスも含まれます。最もユーザー対応の多いフロントエンドはエンドユーザー視点でのSLOになっていくと思いますが、内部サービスでのSLOの対応は各サービス担当との兼ね合いになると思います。(マイクロサービスなのであれば各サービスに担当がいて、そこにリクエストが来ると思います。)
― バックエンドとしてSLO導入してきた岡野さんですが、もしタイミー社にSREエンジニアが入社してきたら、その方にSLO推進を任せますか?
岡野:タイミーの場合は自分で開発したものは自分で運用するルールになっているので、最終的には開発チームにボールを持たせる前提で、SREの方にはプラットフォームチーム的な考えで動いてもらうのがいいプラクティスなのかなと考えています。
岡野:開発の合間に進めていたので、一ヶ月ほど準備期間がかかりましたが、専任であればもう少し早められるかもしれません。
山口:まずは何を計測すべきか、何が一番「信頼性」に影響するか、そもそも、これまで何も計測していない状態で過去との比較ができない場合は、まずはSLIを決めて最低4週間ほど計測してみると良いでしょう。
― APIやサービスが提供する機能の利用頻度は、利用者によって桁が違うため、なかなかSLIが定まりません。
山口:ユーザー特性が複雑で、それに合わせた要件が求められているということであれば、リクエストに付けているアトリビュートなどで振り分けて、それに対してSLOを設定する方法などが可能かと思います。
岡野:私はとりあえずやってみようと行動するタイプなので、最初はよくあるレイテンシや可用性を計測していました。振り返りながら改善していけば良いのかな。運用しながら悩み続けていく形でも問題ないと思います。
山口:100%にしなくていいのかみたいな話ですよね。「これまで計測してきましたが、可用性100%を達成することはないですよ」をスタートポイントにしつつ、具体的に工程を伝えてイメージさせると良いと思います。可用性のSLOを99.99%にする場合、1ヶ月で許容されるダウンタイムは5分以下です。
|
「あなたが今求めてる可用性は、この工程を5分で行うことです。そのうえで、やりますか?やりませんか?」と議論すると、必然的にお金の話になってくると思うので、そこで相手に判断してもらえば良いと思います。
岡野:適切な調整をしたいという話だと思うのですが、私は上げちゃえば良いと思うんですよね。どこかで実現不可能になる。ある程度上げてみて違反する経験を積んでおくのも組織としてはいいプラクティスかなと思います。
シニアデベロッパーリレーションズエンジニア
クラウド製品の普及と技術支援を担当し、特にオブザーバビリティ、SRE、DevOpsといった領域を担当。OpenTelemetryやGoのコミュニティの支援も活発に行っている。「Go言語による並行処理」「オブザーバビリティ・エンジニアリング」「SLO サービスレベル目標」翻訳、「SREの探求」監訳。以前はウェブ、Android、Googleアシスタントなどと各種新規製品・新規機能のリリースと普及に関わり、多くの公開事例の技術支援を担当。好きなプログラミング言語の傾向は、実用指向で標準の必要十分に重きを置くもので、特にGoやPythonを好む。





