ITエンジニアのキャリアに本気で向き合うメディア
ITエンジニアのキャリアに本気で向き合うメディア
目次
■人工知能(AI)と機械学習

2023.08.02 2024.03.05 約5分
「ゲームだけ、と誰が決めた」というキャッチフレーズで出版された「Pythonで学ぶ強化学習」。あれから4年。今、ゲームから飛び出した強化学習は、現実世界で輝いているのでしょうか?
強化学習の弱点と克服方法を実装付きでカバーしています。最近の強化学習関連書籍も含めて他の書籍にはない特徴です。
|
|
本著では(理論上)1週間で強化学習の最先端まで学ぶことができます。まずは書籍の構成と内容を簡単にご紹介します。
|
強化学習の基礎的な仕組み、モデルベース、モデルフリーの基礎的な手法を学びます。

「深層強化学習」とは深層学習 × 強化学習、すなわちニューラルネットワーク(Deep Learning)を組み合わせた学習です。環境の状態を理解し、それに基づいて最適な行動を選択するという強化学習のプロセスを、深層学習によってモデル化すると、Atariのようなビデオゲームで人間を上回るパフォーマンスを達成することが可能になります。
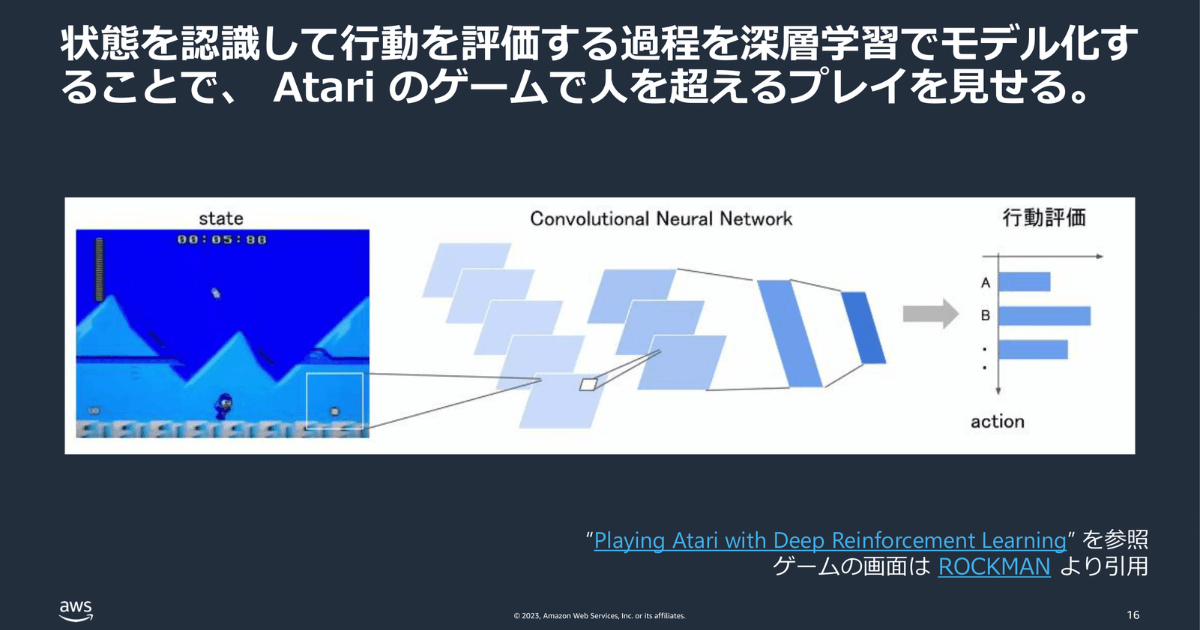
深層強化学習は大量のサンプルを必要とします。例えば、人間がゲームをプレイする場合、数分間プレイすれば、敵キャラクターが近づいてきたらジャンプして避けるのだと学習できます。しかし、深層強化学習を使うと、このような単純なルールを学習するのに、数十から百数時間分のフレームが必要です。
また深層強化学習は、特定の環境やタスクに対して過度に適応してしまう場合があります。ゲームの中で意図しない行動を学習してしまう研究結果もあります。
深層強化学習は同じ手法と条件でも結果を再現することが難しい問題があります。

興味のある方はぜひ、論文をご覧ください。
弱点がわかっているので、具体的にどう改善・克服すべきかを学んでいきます。

さて、タイトルにあるこの問いに答えるために、近年の強化学習がどのように活用されているかを見てみましょう。ここでは、代表的な3つの応用事例を紹介します。
ChatGPTの前身であるInstruct GPTを構築する際、指示に対し適切な出力をさせるだけでなく、人の好む出力をするよう学習させるのに強化学習が使用されています。まず人間がラベル付けしたデータ(テキスト)を4つほど並べて、どれが良いかを聞きます。それをもとに報酬関数を作ります。報酬関数を使い、より人が好むような出力を実行するようチューニングします。この手法は、InstructGPTによって、初めて実施されたものではなく、実は以前から研究されていたものです。もし興味のある方は論文にも目を通してみてください。
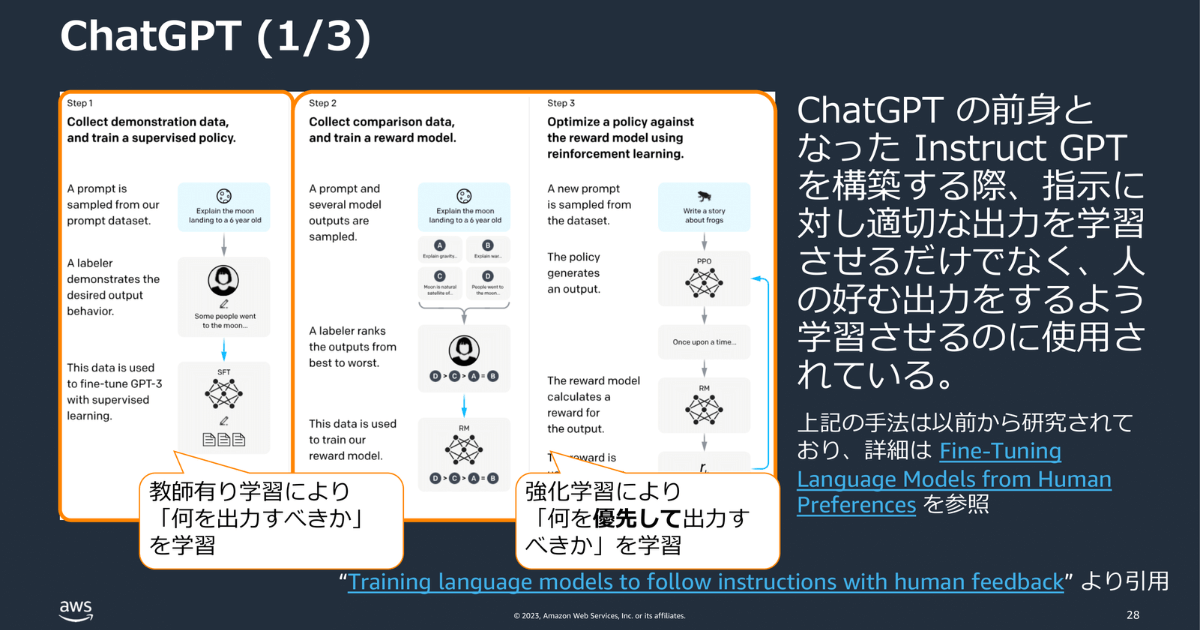
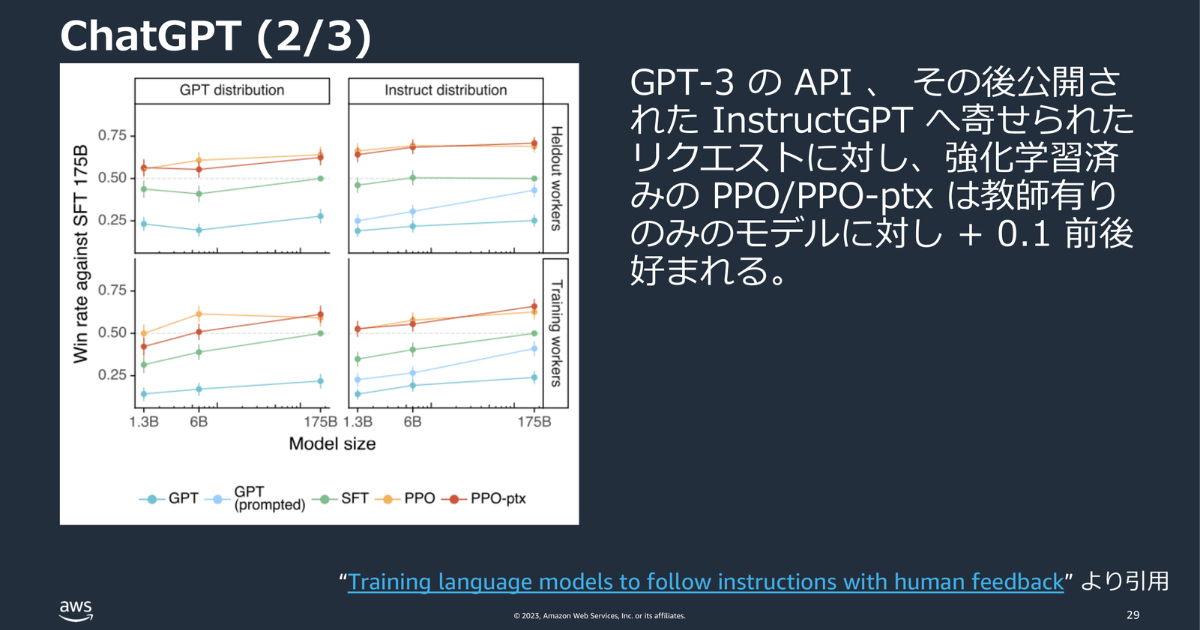
下記のグラフの赤・黄色の線が強化学習済みモデルです。このモデルは、約0.1ほど、人に好まれる出力ができていることがわかります。
GPT4 は、誤解に基づく人の回答(人間が誤解していること)に惑わされず、適切な回答に導く精度が向上しています。

核融合炉では磁気によるプラズマ制御が重要ですが、制御は非常に複雑で、人間が直接行う場合には高度な専門知識と経験が求められ、同時に大きなプレッシャーや不安感からくるミスのリスクもあります。本来、これを制御しようとすれば、かなり複雑なアルゴリズムの組み合わせが必要ですが、強化学習モデルであれば1本で済むため、大きなメリットとなっています。余談ですが、OpenAI の CEO が核融合炉への投資を検討しているというニュースがありました。強化学習が応用できると考えているからかもしれません。

核融合炉ではありませんが、化学プラントの制御を日本で成功させた事例です。

これらの事例は、先進的な強化学習の手法ではなく、枯れた手法を活用しています。
目的を事例 (データ) でなく関数 (ルール) で表現したい場合、強化学習は有効です。
|
前述した深層強化学習の弱点のひとつ「サンプル効率」は、事前学習を経て転移学習をすることで効率を改善する研究がなされています。2020年には、蓄積されたゲームプレイのフレームを事前に予習してから、実際にゲームをプレイし、学んでいくアプローチが実験されています。

今年はもう一歩進み、事前学習と転移学習を分けずに、一緒に事前学習済みのデータを使ってオンライン学習をする手法が編み出されました。
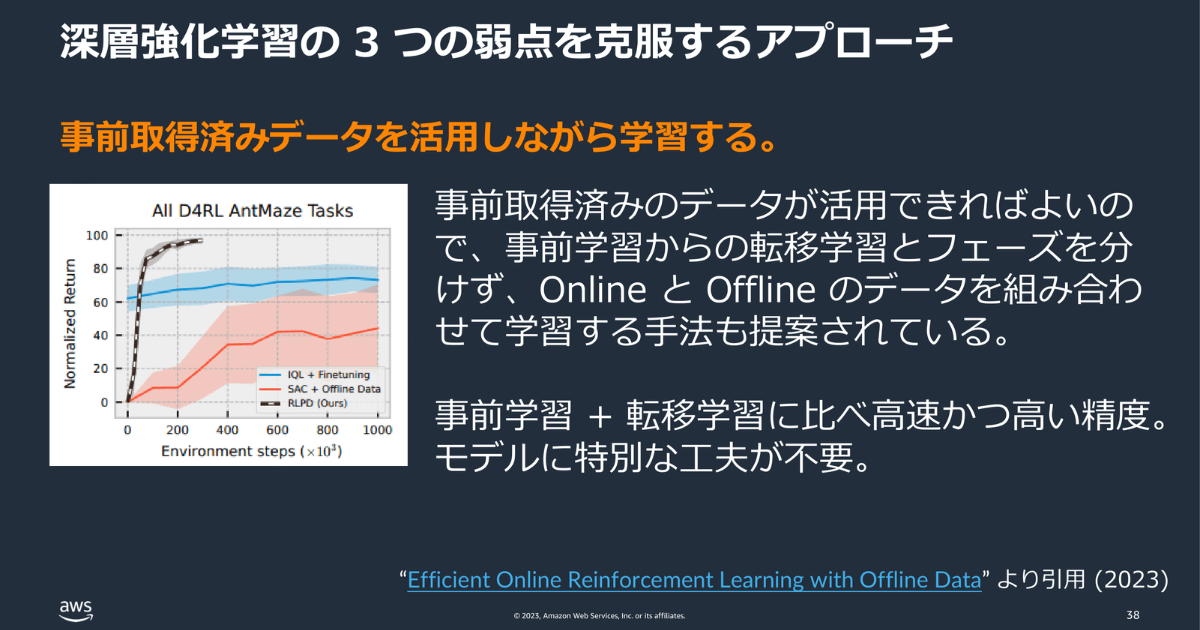
さらに安定する教師有り学習の枠組みで強化学習を解く研究も行われています。

事前に人間やエージェント自身で取得したデータの活用が鍵になってきそうです。
強化学習は、事前に取得済みのデータ(例えばプレイ動画など)があれば、既存の手法よりも効率的に学習が進められることがわかっています。研究が進むことで、応用の範囲が広がることが期待されます。まだどのように高速で動くシミュレーターを作るのかは課題です。画像・動画などからデータを簡単に生成することができれば、よりこの分野の発展に寄与していくはずです。

ここからはイベント参加者からの質問にリアルタイムで回答した様子をレポートします。
教師あり学習 × 強化学習についてもう少し教えてください
― 強化学習のタスクで、教師あり学習を組み合わせるというのがよくわかりません。データはどのようにするのでしょうか?または、どのような例が教師あり学習+強化学習ができるのでしょうか?
本講演の中で紹介した2つの方法を改めて紹介します。
| データ収集 → 教師あり学習 → 強化学習 という流れです。データ収集は、GPT-3に寄せられたデータを使用します。リクエストと人間が好むレスポンスをペアにし、データを収集、形成します。教師あり学習:収集されたデータセットを使用してトレーニングします。強化学習は、最初の教師あり学習の後、モデルのパフォーマンスをさらに向上させるために強化学習します。データセットから報酬関数を作成して強化学習を行います。 |
| ゲームプレイのログを事前に録画しておき、そのデータを使用して強化学習を行う方法です。例えば、ゲームの状態がフレームAからフレームBへ移ったときに、どのようなアクションを取ったのか予測します。学習に必要なフレームと行動のデータはゲームのプレイログに記録されているので、教師有り学習で学習することができます。 |
強化学習の応用研究で、最も難しいのはどの部分?
― アバウトな質問ですが、強化学習の応用研究をするとき、最も難しいのはどの部分でしょうか。問題設定の仕方なのか、アルゴリズムの選定方法か、報酬関数の設定方法など、考えるべき事項が複数あると思いますが、2023年7月時点でまずはこれを試すと良い、というような観点がもしあれば教えていただけないでしょうか。
最も難しいのは、報酬関数の設計です。報酬関数が形成できてしまえば、既存の枯れたアルゴリズムでも解くことは可能です。さらに言うと、報酬関数を解くためには、そのシミュレーターが必要のため、何回も試行錯誤できる環境を作れるかどうかが次の問題になっていきます。
現実世界で一定以上の品質を確保するために、必要なことは?
「人間が環境を定義しきれない」というのは「報酬関数を設計しきれない」ことと捉えてお話します。報酬関数を設計しきれないなかで、どのようにクオリティの高い強化学習のエージェントを作るのか。これはなかなか難しい質問ですね。最近の研究に照らし合わせると、やっぱり事前学習、オフライン学習をいかにうまく使うのかが、ポイントになりそうです。事前学習ができていれば一定の品質と言えるため、どれだけ事前学習で精度を高めてからオンラインで学習できるかがポイントだと思います。
「Pythonで学ぶ強化学習」は実践的ですか?
― 「この書籍を読んで、Pythonコードを試していけば、実務・実開発で使えますか?」
そのままは使えません。書籍は基本的なアルゴリズムを紹介しています。これらの基本的な知識は、実際の問題解決に向けた第一歩となります。具体的な応用やチューニングを行う前に、まずはこれらの基礎を理解することが重要です。基礎がわからない状態で応用やチューニングはできないので、まず書籍で基礎を学んで欲しいです。
おすすめのシミュレーターは?
普段の業務に強化学習を活かしていますか?
現在の業務はプロダクトマネジメント(PM)寄りで、私自身が直接強化学習のアルゴリズムを作成することはありません。しかし、強化学習が現実の世界で役立つ企業が増え、強化学習が最適な解決策となるプロジェクトチームを支援する機会を夢見ています。
人間のフィードバック(RLHF)を理解する方法
― ChatGPTやGPT-4で採用されている強化学習から人間のフィードバック(RLHF)を完全に理解するためには?
RLHFを理解するためには、まず強化学習の基本的な概念について理解しておくことが重要です。そのうえで、最新かつ正確な情報を得るためには、OpenAIの論文を読むことをおすすめします。RLHFは人間のフィードバックを使用しますが、私が論文を読む限り、RLHFを実装するために特別な理論的知識が必要なわけではないため、基本的な強化学習の知識とOpenAIの論文を読むことで理解を深めることができます。
ChatGPTの精度が落ちているのは本当?
― スタンフォード大学の研究で、ChatGPTの性能がここ数カ月の間に大幅に低下している可能性があるとのこと。これは本当なのでしょうか?
3月に公開されたまさにその時のモデルと現在のモデルを比較していないので何とも言えません。現在、過去のモデルは意図的に指定する必要があります。運営上、古くなったモデルにリソースを割り当てる必要はないと判断することもあるでしょう。とくに GPR-4のモデルは、維持を考えると胃が痛くなるような大規模なモデルなので、性能を犠牲にしたリソースの削減が行われても不思議ではないと思います。良く使われるモデルにリソースを割きたいのが現実なので、あまり使われていない機能のリソースを削減する可能性はあると思います。参照 How Is ChatGPT’s Behavior Changing over Time? | Stanford University UC Berkeley
教師なしモデルと強化学習の事例は?
教師なし学習を利用した事例として、教師なし学習による表現学習を行う World Models という手法があります。強化学習の難しさは「環境の理解」と「行動の最適化」の学習を同時に達成することです。 World Models は、その2つの学習をモデル上、分けて学習しています。これにより、全体の学習プロセスがより効率的でスムーズになります。
強化学習の理想的な学習法は?
理論と実装どちらを優先して勉強するかという話もありますが、これは好みで決めて良いでしょう。理論は数学的で深く面白さがありますし、エージェントを動かすことに面白さを感じるなら実装でも良いですよね。どちらのアプローチも尊重されるものなので、私は「理論がわからないのに使うな」と言いたくないです。
OpenAI 以外の強化学習の成功事例は?
DeepMind や Berkeley AI などの研究機関で強化学習の成功例があります。DeepMind は、AlphaFoldというたんぱく質の構造を予測するモデルで医療や化学の分野で貢献しています。Berkeley AI は、特にロボティクスの分野で強化学習の応用を試みています。OpenAI も実は数多くのトライアンドエラーを繰り返しています。ルービックキューブを解くAIや、マルチプレイヤーゲームのAI「OpenAI Five」など、多くの挑戦と試行錯誤の結果、現在のChatGPTの成功を手にしています。ChatGPTは、挑戦の積み重ねの成果といえると思います。
「機械学習を実用するならAWS」の認知拡大をミッションにプロダクト開発チーム向けワークショップ「 ML Enablement Workshop 」を実施しており、資料は全て GitHubで公開しています。自社プロダクトの成長 を狙うチームが、機械学習の使いどころを学び、実行可能な計画 を立てられるようになることが目的の無償ワークショップとなります。関心のある方はお問い合わせください。https://youtrust.jp/recruitment_posts/4ec6e205c5576ed9fc80814160f84a65
https://speakerdeck.com/icoxfog417/gemukarafei-bichu-sitaqiang-hua-xue-xi-ha-jin-hui-iteiruka


機械学習デベロッパーリレーションズ
「機械学習を実用するならAWS」の認知拡大をミッションにプロダクト開発チーム向けワークショップ「 ML Enablement Workshop 」を推進。 10年以上の業務コンサルタント経験、また研究開発していたテーマをプロダクトとしてリリース経験を活かしながら活動中。


