ITエンジニアのキャリアに本気で向き合うメディア
ITエンジニアのキャリアに本気で向き合うメディア
目次
■キャリアとスキルアップ

2024.05.07 2024.06.19 約4分
キャリアの不安を解消しませんか?
キャリアにお悩みの方は、「Forkwell エージェント」をご活用ください!私たちが、無理に転職を勧めることはありません。エンジニアが転職のプレッシャーから解放され、自信を持って新たなキャリアを歩む手助けをお約束します。どの部分を強化し、どのように弱点を克服するのか、魅力的なポートフォリオの作成方法などをアドバイスいたします。
Forkwell エージェントに相談してみる(無料)本イベントの事例公演はこちら
東証システム障害とは、2020年10月1日に東京証券取引所で発生した全面的な取引停止事故です。この一連の出来事は、富士通製のNASシステムの「テイクオーバー機能」が機能しなかったことや、富士通の提供したマニュアルの不備、東証の不十分なテストなどが原因でした。
このインシデントは、多くのメディアによって批判的に報道される一方で、エンジニア界隈ではインシデントの発生から対応、公表、記者会見に至るまで「誠実な対応」として評価され、東証の透明性が称賛される声も多く聞かれました。今回は、インシデントの詳細と調査報告書を基に、東証システム障害からエンジニアが得るべき教訓について深掘りします。
東京証券取引所は、上場時価総額が約6.5兆ドル(約1000兆円)に達する世界第5位の市場です。この大規模な市場を支えているのが、富士通製のアローヘッドシステムです。
アローヘッドは、一般的なインターネットと違い、アローネットという専用ネットワークを使用します。このアローネットを通じ、取引参加者や市場情報を利用するユーザーが接続します。アローヘッドシステムは現在、数百台のサーバーによって1日当たり約3億2000万件のトランザクションを処理する巨大システムです。
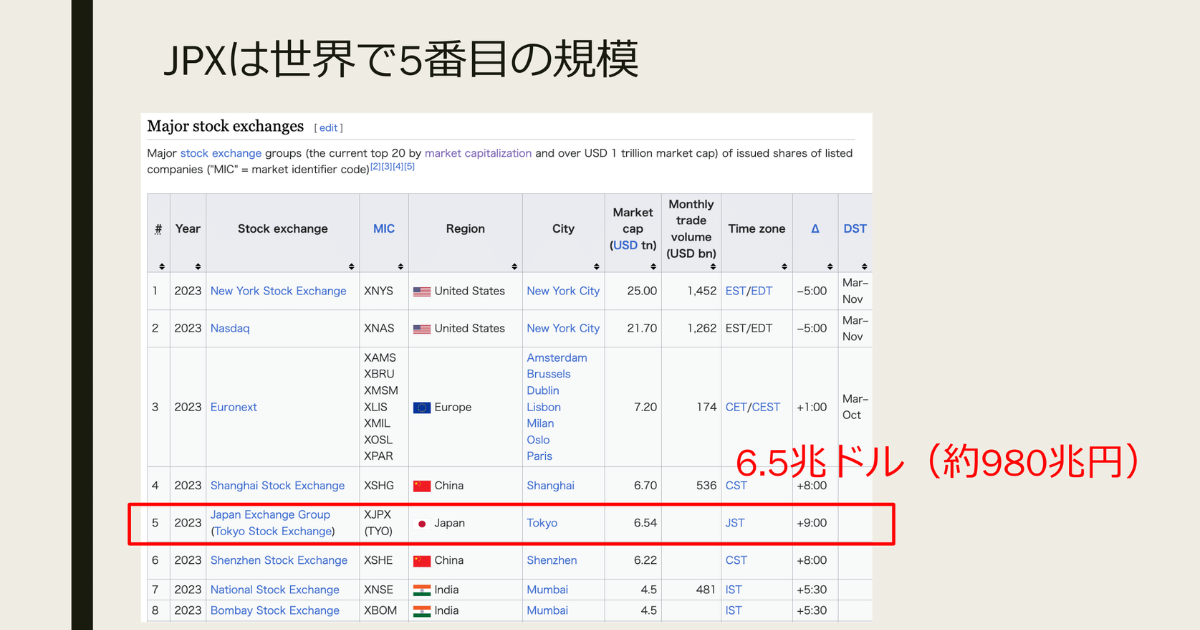
今回の話のメインとなるNAS(Network Attached Storage)は共有ディスク装置で、東証ではNAS1号機とNAS2号機の2つのNASシステムを稼働させています。一方の装置に問題が発生した場合には、もう一方の装置が自動的に機能を引き継ぐように設計されています。
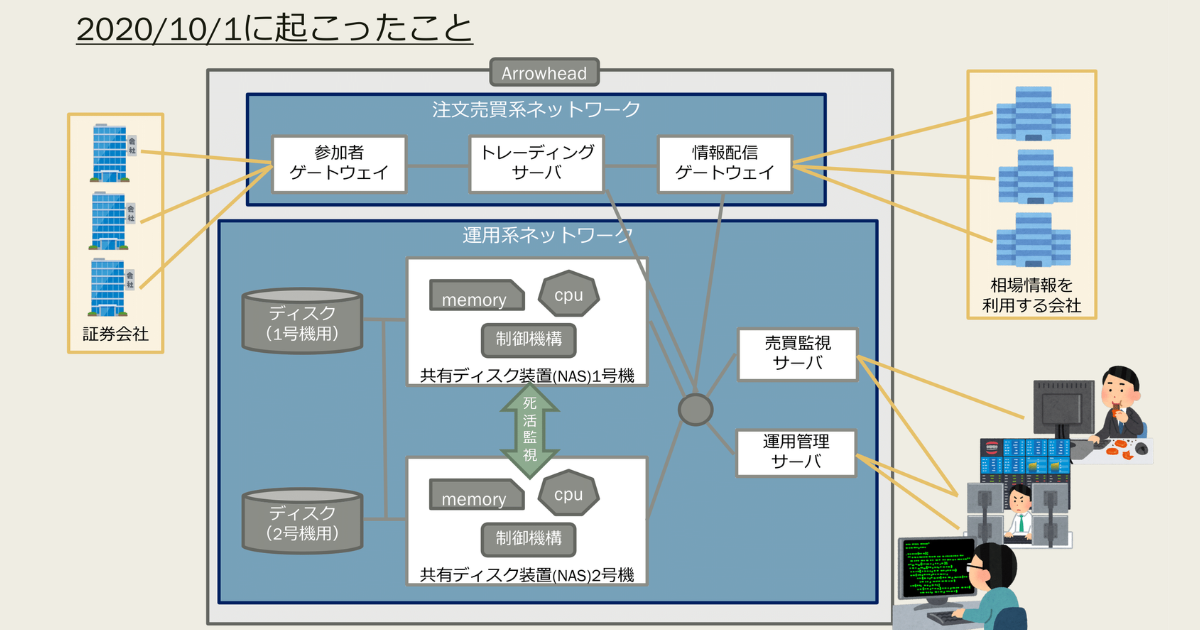
▲アローヘッド・アローネットを模式的に表した図
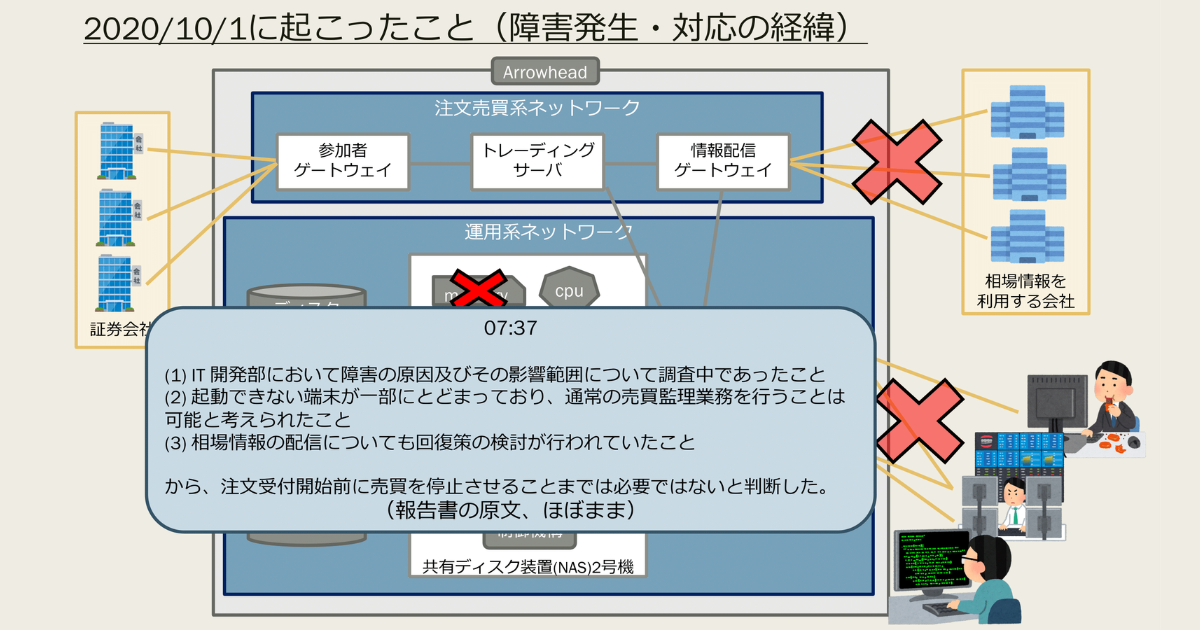
東証は、午前8時に注文受付、午前9時から取引開始されます。2020年10月1日 7時4分、NAS1号機でエラーが検出されました。本来実行されるはずのNAS2号機への切り替えが作動せず、東証はすぐに富士通へ連絡を取り、障害対応のインシデントプロセスを開始。本来実施されるべきいくつかのプロセスが動作していないことを7時半までに調査し、7時37分には障害対策本部を設置しています。この段階では、障害の影響範囲が把握されておらず、使用不可能な端末が一部であること、まだリカバリの手段が残されていることなどから、売買停止に踏み切るほどの状況ではないと判断されました。
エラー発生
07:04:NAS1号機でエラーを検出。NAS2号機への切り替えが実行されず
ログイン障害
07:06:一部端末で売買監理画面および運用管理画面へのログインが不可能になる
対策開始
07:10:富士通に連絡し、共同で障害対応と影響範囲の調査を開始
07:10 – 07:30:経路維持電文や通信開始電文、銘柄情報の更新などの処理が行われていないことを確認
対策本部設置
07:37:横山JPX CIO指揮のもと障害対策本部を設置。社内に障害情報を通知
注文受付とログイン問題の継続
08:00:証券会社からの注文は正常に受け付けるも、すべての管理画面へのログインが不可能に
売買停止の決定と通知
08:30:相場情報配信システムが回復しない場合、9時からの売買停止を決定し発表
08:37:取引参加者に売買停止を通知
08:54:証券会社とのロードバランサ接続を断つ。ただし既に受け付けた注文の処理は継続
最終的なシステム停止
09:00:約定情報の一部が誤って配信されたため、相場情報配信側のロードバランサを遮断
09:11:最終的な切り離し措置として、相場情報配信を完全に停止
システム復旧
09:26:NAS2号機への強制切り替えに成功。売買監理画面と運用管理画面が復旧
終日取引停止の決定
11:00 – 11:45:経営者と経営幹部が会議を開催し、終日の売買停止を決定、Webサイトに公表
8時の時点で、アローヘッドシステムが注文を正常に受け付けていたため、証券会社の担当者たちはシステムが
正常に動作していると認識していましたが、裏ではシステムの被害が拡大しており、全ての売買監理画面や運用管理画面にログインできない状態が発生していました。そこで、事前に準備されていたコンティンジェンシープランの実行が決定されました。

東京証券取引所では、アローヘッドシステムの停止に向けて3つの手段を用意していました。
しかし、ログインできない問題により1番と2番の方法は失敗しました。また、3番の方法もNASに依存する処理のため失敗しました。このため、証券会社とのロードバランサ接続を遮断するという苦肉の策により、新たな注文受付の中止には成功しましたが、アローヘッドそのものが止まったわけではないので既に受け付けた注文に対する約定処理は継続されました。午前9時にアローヘッドの約定処理が走り、約定情報が情報配信ゲートウェイから誤って配信されたため、最終的に9時11分に情報配信を担うロードバランサを遮断しました。これによりシステムは完全にオフラインとなり、配信された約定情報の無効化が通知されました。
この時点で、NAS1号機に問題があることが確認されたため、NAS1号機を強制的に切り離し、NAS2号機への切り替えを試みました。しかし、様々なコマンドを試してもうまくいかず、サーバールームに直接入り、LANケーブルや電源ケーブルを引き抜くという物理的な切断も検討されていました。この一連の対応の中で、9時26分に実行したコマンドが成功し、NASへの強制切り替えが完了。これにより、9時半頃には売買監理画面および運用管理画面が復旧し、アローヘッドシステムは正常に復旧しました。
システムが復旧し、売買監理画面と運用管理画面が再び稼働しました。そこで、午後の取引再開の可否を証券会社にヒアリングしましたが、対応可能であると回答したのは、わずか38%のみ。これでは市場の健全な運営が難しいと判断し、当日の市場再開は断念されました。
公表されている情報から整理してみます。まず、事故当時の東証のアローヘッドシステムのNASは富士通 ETERNUS NR 1000シリーズを使用しており、これには自動的にシステムを切り替える「テイクオーバー機能」が備わっています。
テイクオーバー機能は、2つの異なる方式があります。
1. 標準テイクオーバー方式
この方式では、システムはお互いに「生存通知電文」を送り合い、互いの稼働状況を確認します。この通信が15秒間途切れると、もう一方のシステムが活動を停止したと判断され、自動的に処理を引き継ぎます。
2. 即時テイクオーバー方式
こちらは、片方のシステムが「パニック通知電文」という特定の信号を送ることで、即座に処理の引き継ぎが行われる方式です。この信号が送られた場合、受信したシステムは即座に主要な処理を開始します
「即時テイクオーバー方式」の有効化は、「on_panic」というパラメータによって設定されます。この設定が「True」の場合は即時テイクオーバーが有効化され、「False」の場合は無効化されます。なお、標準テイクオーバーはこの設定に関わらず常に有効です。しかし、2015年以降のシステム仕様変更により、「False」設定では、パニック通知電文を受信すると標準テイクオーバーも無効化されるようになりました。これは以前の設定と異なり、新たな電文の受信で両方のテイクオーバー機能が停止することを意味します。東証は、初代アローヘッド導入時(2010年)から「on_panic=False」で運用していましたが、2015年の仕様変更を認識せずに同様の設定を続けていたため、NAS1号機からNAS2号機への自動切り替えが行われなかったのです。この設定の誤認が今回の障害時にテイクオーバーが発生しなかった根本原因となりました。
アローヘッドシステムは、2010年に初代機が導入された際、NetApp社製のONTAP7を採用していました。このシステムでは、「標準テイクオーバー」機能が「on_panic」パラメータの設定値に関わらず常に有効であり、初期設定値は「False」でした。東証の要件である「30秒以内に切り替わること」がこの設定でも満たされたため、そのまま導入されました。
2015年に2代目のアローヘッドが稼動開始されましたが、この時にOSがONTAP8にアップデートされたことにより仕様変更が行われ、パニック通知電文を受け取った場合に標準テイクオーバーが無効になる変更が加えられました。しかし、この仕様変更はNetApp社から富士通の製品担当者には伝達されておらず、テストプロセスでは「on_panic=True」の状況のみが検証され、重要なテストケースが見落とされていました。2019年に3代目のアローヘッドが導入された際も、システムのNASはONTAP9にアップデートされましたが、富士通に納品された仕様書には「on_panic」設定値に関する変更の記載がなく、引き続きONTAP7時代の認識で運用されていました。その結果、5年間もの間、東証は変更を認識せずに「on_panic=False」の設定でシステムを運用し続けました。この長期にわたる認識の誤りが原因で、2020年10月1日にNAS1号機に障害が発生した際、システムは自動的にNAS2号機に切り替えることができず、大規模なシステム障害につながりました。
NAS1号機でメモリ故障が発生し、NAS2号機へパニック通知電文が送信される
システムの設定が `on_panic=False` であったため、即時テイクオーバーが発動しなかった
NAS1号機とNAS2号機間の相互監視は0.5秒おきに行われていたが、パニック通知電文の受信後にはこの監視が途絶える。通常は、通信途絶後に標準テイクオーバーが発動するが、パニック通知電文受信時の設定 (on_panic=False) により、標準テイクオーバーも無効化されてしまった。
結果として、NAS1号機からNAS2号機への自動切り替えは行われず、システム全体が利用不可能な状態に陥った。この設定の誤りが原因でシステム全体の停止を招く事態につながった。
調査委員会は、不備のあるマニュアルを作成した富士通の責任が重いと指摘しています。マニュアルの不備が、障害時の適切な対応を妨げた主要因と見なされています。
東証もまた、導入時のテストで網羅的なテストケースの洗い出しと検証が不足していたため、一定の責任があるとされています。もしテストケースが追加されていれば、事故を防げた可能性があります。
NAS2号機への手動切り替えに1時間半もかかったことについては、事前に準備されていなかった対処コマンドの不足が指摘されています。これが迅速な対応を妨げたとされています。
事故当日の朝8時からの注文受付は、その時点での状況に鑑みれば妥当だったと評価されています。
「8:30までに復旧しなければ売買を停止する」という判断は、当日の状況を鑑みれば適切だと評価されています。
売買停止に至る判断ポイントについては、今後より明確にしておくべきだとの提言があります。
ロードバランサを遮断せざるを得なかった事態は、アローヘッドシステムの設計に問題があることを示唆しています。特に、「緊急用売買停止処理」が緊急時に機能しなかったことは、システム設計の重大な欠陥であると評価されています。
いくら東証といえども、防ぎようのない事故は発生します。そのうえで重要なのは障害が発生した際にいかに迅速にシステムを復旧できるかです。NASをはじめとするすべての機器の設定値を見直し、定期的に点検を行うことで、システムの整合性と効率を保つことが大切です。
マニュアルが実際のシステム動作と一致しているかを確認し、切り替え機構を持つ機器については、マニュアルに基づく切り替え手段と手順を整備する必要があります。
継続的かつ網羅的なテストを実施し、市場参加者(証券会社など)も含めた訓練を日常から行うことで、実際の障害発生時に迅速かつ効果的に対応できる体制を築くことが求められます。
緊急時に確実に機能する売買停止手段を確保し、緊急用の売買停止処理が障害時に正確に動作するようにする必要があります。
市場停止(注文受付や売買の停止)や市場再開の際のルールを明確に整備し、すべての関係者が理解しやすいガイドラインを設ける必要があります。
調査報告書は、インシデントの内容を深く理解し、あらゆるリスクに備えるための非常に貴重な資料でした。実際にインシデントが発生した際の関係者の努力や対応が報告書を通じリアルに感じることができます。
この事件から学ぶべき教訓は、チームの柔軟性と対応力の重要性です。障害対応チームの柔軟性や対応力が事業を左右するといっても過言ではありません。どんなに事前に準備をしても、すべての事態を予測することは不可能です。未知の問題に直面した際に迅速かつ効果的に対処できる「ブルーチーム」の重要性を理解する貴重な機会といえるでしょう。
東証がSREによるレジリエンス向上に挑む理由。過去のシステム障害から何を学んだのか?(前編) ソフトウェア品質シンポジウム2022
システム障害に係る独立社外取締役による調査委員会の報告書について
転職は思ったよりも、時間がかかる
年収800万円以上のハイキャリアでも、42%が転職に1年以上かかっています。
技術力が高いほど、転職先が限定される
スキルや志向が明確なほど、マッチするポジションは限定されます。
ハイキャリアでも、面接には落ちる
素晴らしいキャリアでも面接に落ちることは珍しくありません。メンタル対策や面接の振り返りをサポートします。
自分のペースで進めたいなら「スカウトをON」
エージェントに頼らずスカウトメールから直接応募も可能です。
Forkwellエージェントは、企業選びから面接対策まで、あなたの転職活動を徹底的にサポートします。「経験チャート」機能を利用すれば、たった3分であなたの経歴を作成できます。

取締役CTO
新卒からフリーランスエンジニアとして活躍し、Fintechベンチャーでは役員として複数金融システムの立ち上げをリード。個人プロジェクトとして政治資金データベースを開発・公開|東大情報理工修士 / IPA未踏クリエーター



