ITエンジニアのキャリアに本気で向き合うメディア
ITエンジニアのキャリアに本気で向き合うメディア
目次
■クラウド&インフラストラクチャ

2022.05.08 2023.12.14 約3分
Forkwell が主催する技術イベント「Infra Study」。今回は「VM時代の開発とCloud Native時代の開発」というテーマで開催しました(開催日:2020年 5月20日)。第2部では、青山さんの基調講演から「VM時代と Docker / Kubernetes を比較したパート」を紹介します。Docker によって開発者とインフラエンジニアの体験がどのように変わったかや、CAPS のコード化と Kubernetes のコード化の違いが、わかりやすく解説されています。
今回は、VM時代と Docker / Kubernetes を比較して紹介します。
まず Docker が大きく寄与したものとして、コンテナのイメージ化が挙げられます。アプリケーションとアプリケーションを実行するための環境を、ひとまとめにイメージ化できたところですね。かつコンテナ化により、Immutable Infrastructure もさらに強固に徹底できたのも一つのメリットかなと。

従来の環境だと、Terraform などで VM を起動し、Chef や Ansible でセットアップして、そのあとに Jenkins でアプリケーションをデプロイするのは結構時間がかかるので、あまりやらないパターンかなと。
これをもう少し進化させると、ベースイメージを作り、Terraformで VM を起動したら、あとアプリケーションデプロイするだけにするあたりが、だいたい現実的な解かなと。今のコンテナ時代みたいに、アプリケーション自体を VM のイメージのなかに入れて起動するのは、あんまりやっていないと思います。

Docker の時代では、Dockerfile でイメージ自体をビルドするところは、開発者側ができるような作業です。ここら辺も組織のポリシーによるとは思うんですけれども、個人的にはDockerfile を書くまでを開発者サイドでやるといいと思います。
あとはイメージ化したものを、Kubernetesへのマニフェスト記述により、コンテナとして起動できると。このコンテナのイメージ化のなかにアプリケーション自体も入ってるので、完全に同じような状態で起動が保証されるようになりました。これがインフラから見たときのビルドからデプロイの変化ですね。
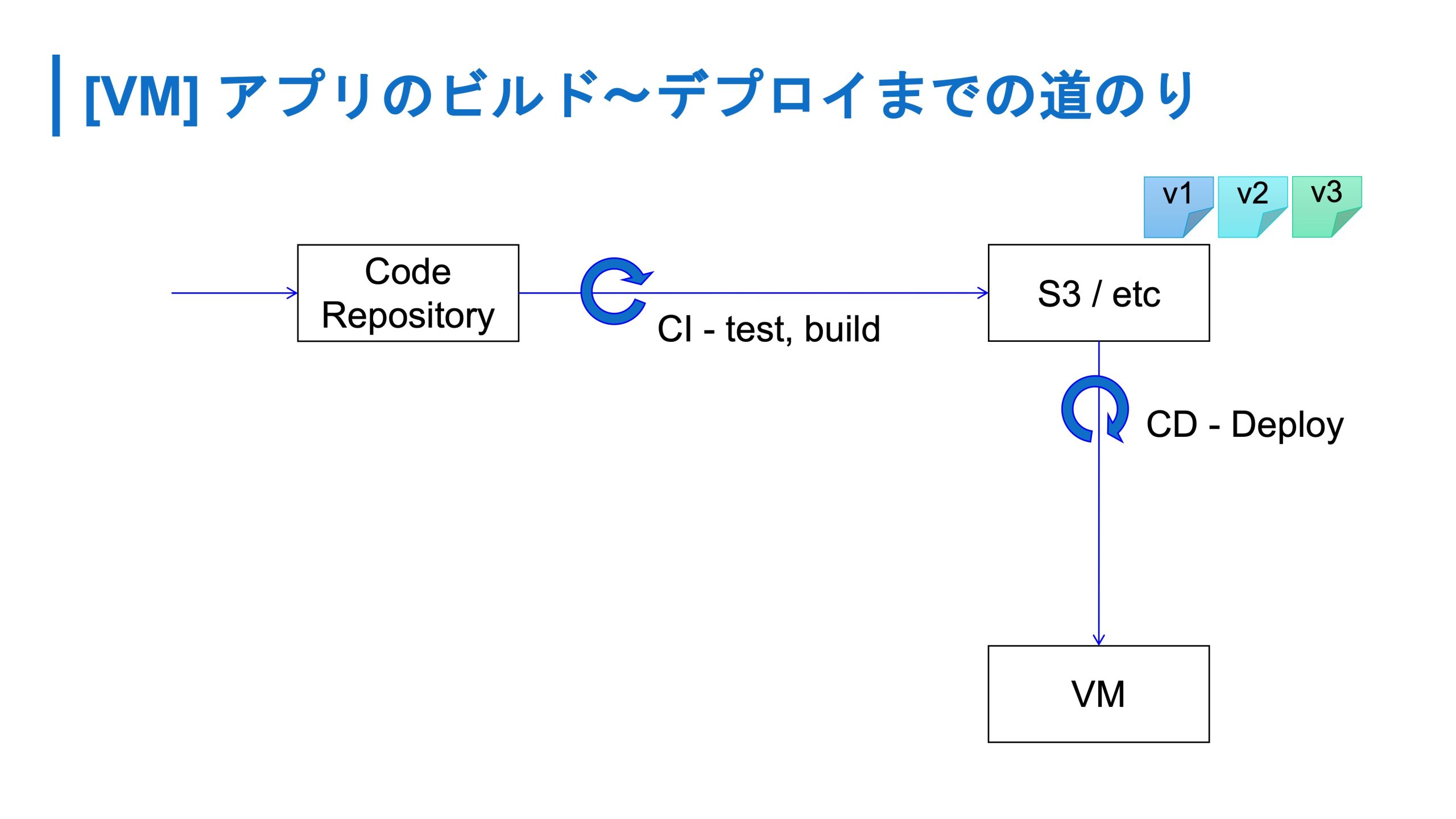
開発者側から見ると、従来はコードのリポジトリに対してプッシュすると、CI が走ってバイナリをどっかに置いておき、 CD で VM にデプロイするような流れでした。
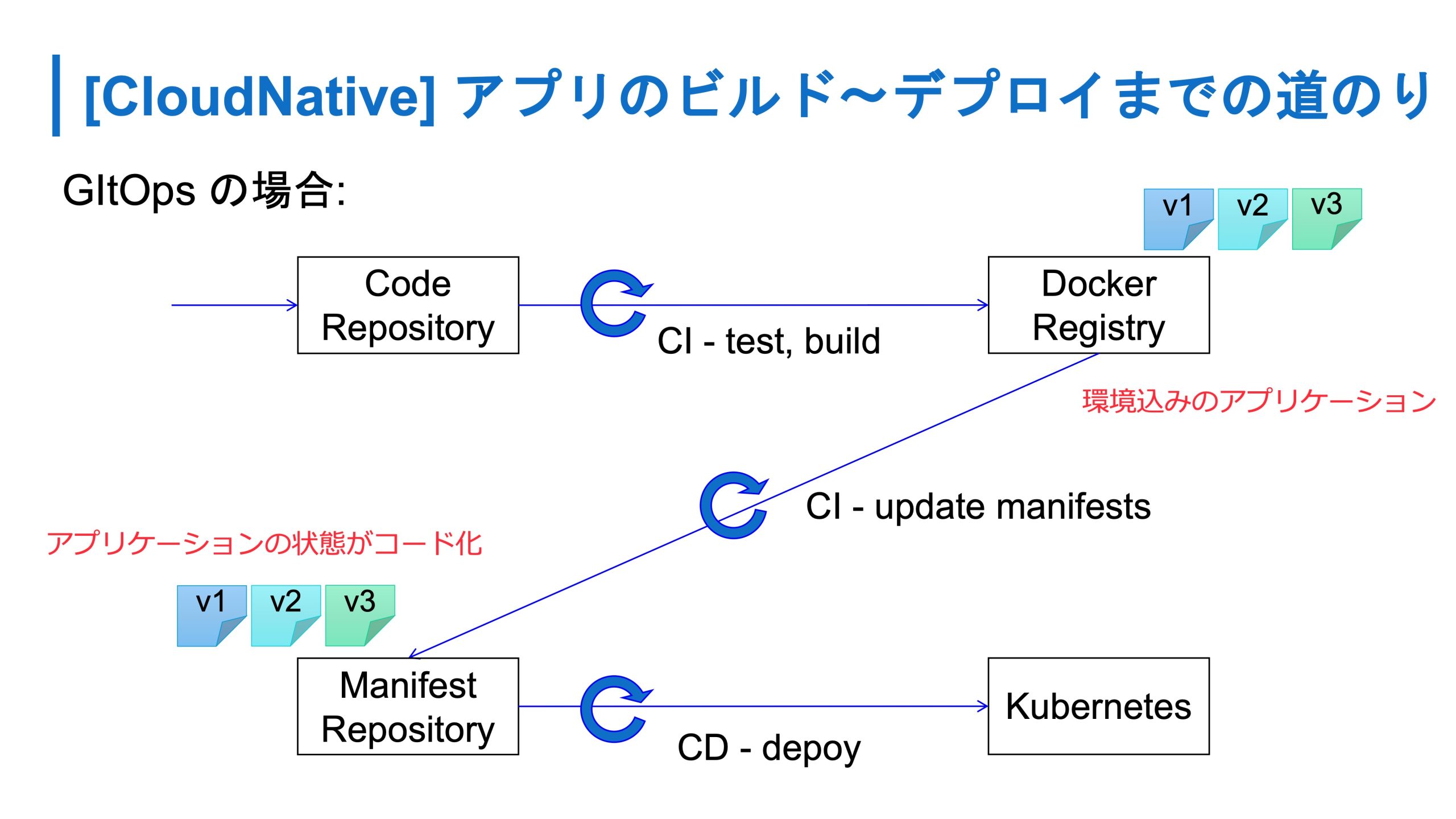
Kubernetes の環境になると GItOps を使うことが多いですが、アプリケーションエンジニアから見るとコードに対してプッシュすると、コンテナイメージがつくられ、コンテナイメージを使うように、インフラの構成情報が変更されます。
どのアプリケーションがクラスタに登録されているかがコードとして見れますし、Docker のコンテナイメージのレジストリ置き場には環境込みのアプリケーションが置かれているので、非常にわかりやすい状態になったと思います。

またアーティファクト自体はコンテナイメージとマニフェストだけなので、基本的に外部に依存する部分さえ用意すれば、どこでも手元でコピーを作れる点がメリットです。今は外部に依存するところも、コンテナで補えます。
アプリケーション実行のベストプラクティスのコード化について話します。

2つ目が Kubernetes です。アプリケーション実行を念頭に置いたベストプラクティスがコード化されているかなと思います。従来の Chef とか Ansible のコード化はあくまでもインフラのものなので、構築スクリプト的なんですね。
一方で Kubernetes のコード化は、アプリケーションをどう動かすかにフォーカスしています。また、安定的に動かすためのベストプラクティス的な設定群です。

たとえばコンテナを動かす設定は、アプリケーションが前提となるようにどのアプリケーションを動かすかを定義して、それに対し環境変数などで環境を切り分けるような設定もかけます。
他にはヘルスチェックやリソースの割り当て、アプリケーション実行時のライフサイクルに関する設定、こういったものがすぐに直接書けるところが、アプリ実行のためのコード化になっていると思います。
Kubernetes を使う際、コンテナの停止処理のお作法みたいなものがあります。停止時は、SIGTERM が送られてきて、その後、一定時間後に SIGKILL が送られるというコンテナのライフサイクルがあります。
Kubernetes を使うと、こういうライフサイクルの対応を必然的にやることになるので、アプリケーション開発のベストプラクティスのレールにある程度乗れるのもいいところだと思います。
インフラの抽象化について話します。

Kubernetes はインフラレイヤーを抽象化しているので、インフラエンジニアじゃなくても、開発者側でも触りやすくなっています。大なり小なりあると思いますが、従来の環境だと、ロードバランサの連携は、スクリプトや手動管理、IPアドレスも自分たちで管理していたと思います。

ただ Kubernetes になると、こういったコンテナのIPアドレスは一切管理しません。コンテナにはラベルがついていて抽象的に管理します。ロードバランサとの連携もこのラベルをベースとして、 Kubernetes がメンバーの更新などを自動的にやってくれます。
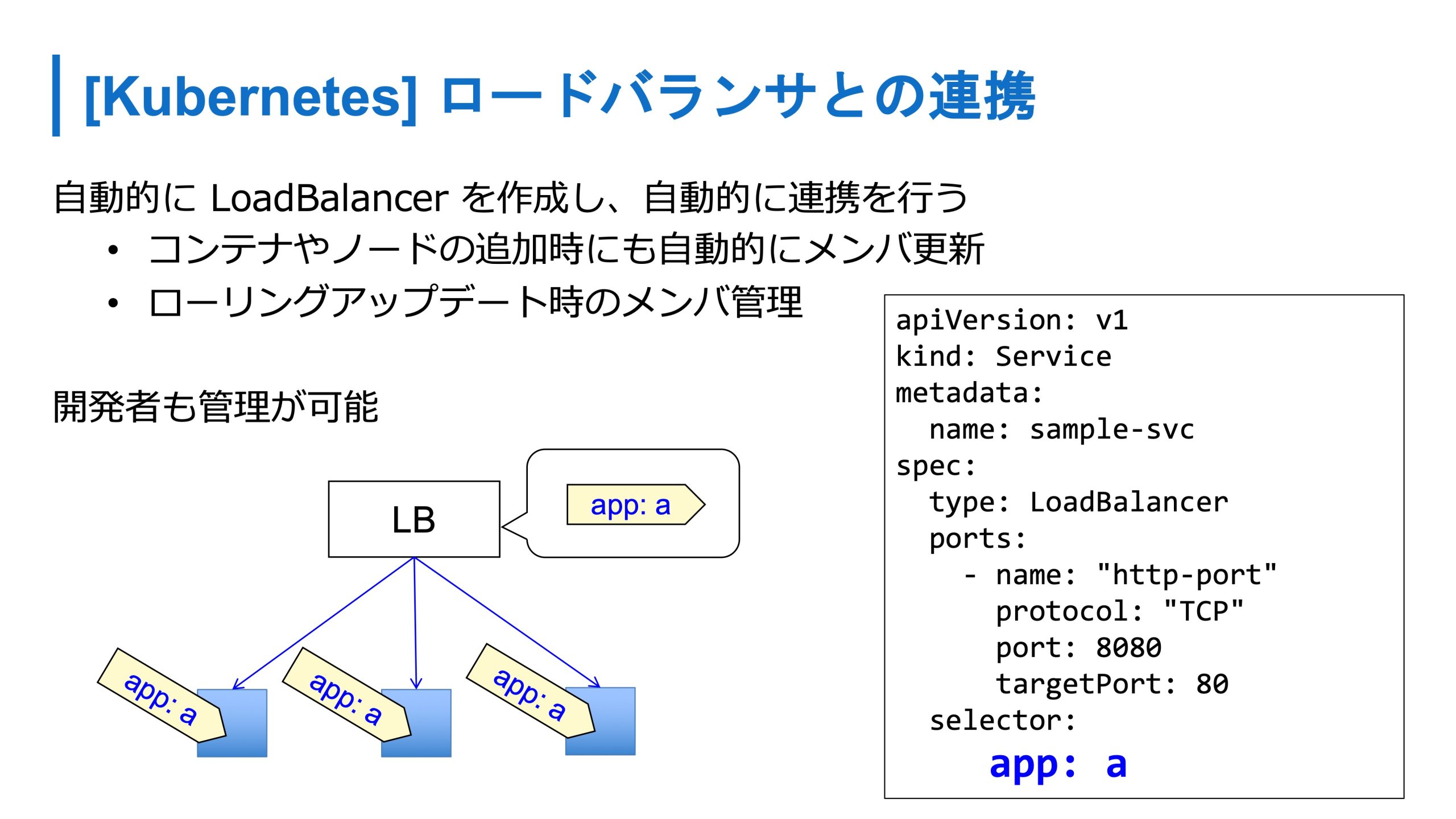
この2つのリソースを作ると、コンテナが3つ立ち上がり、ロードバランサが自動的に作られて、メンバーの管理をしてくれます。
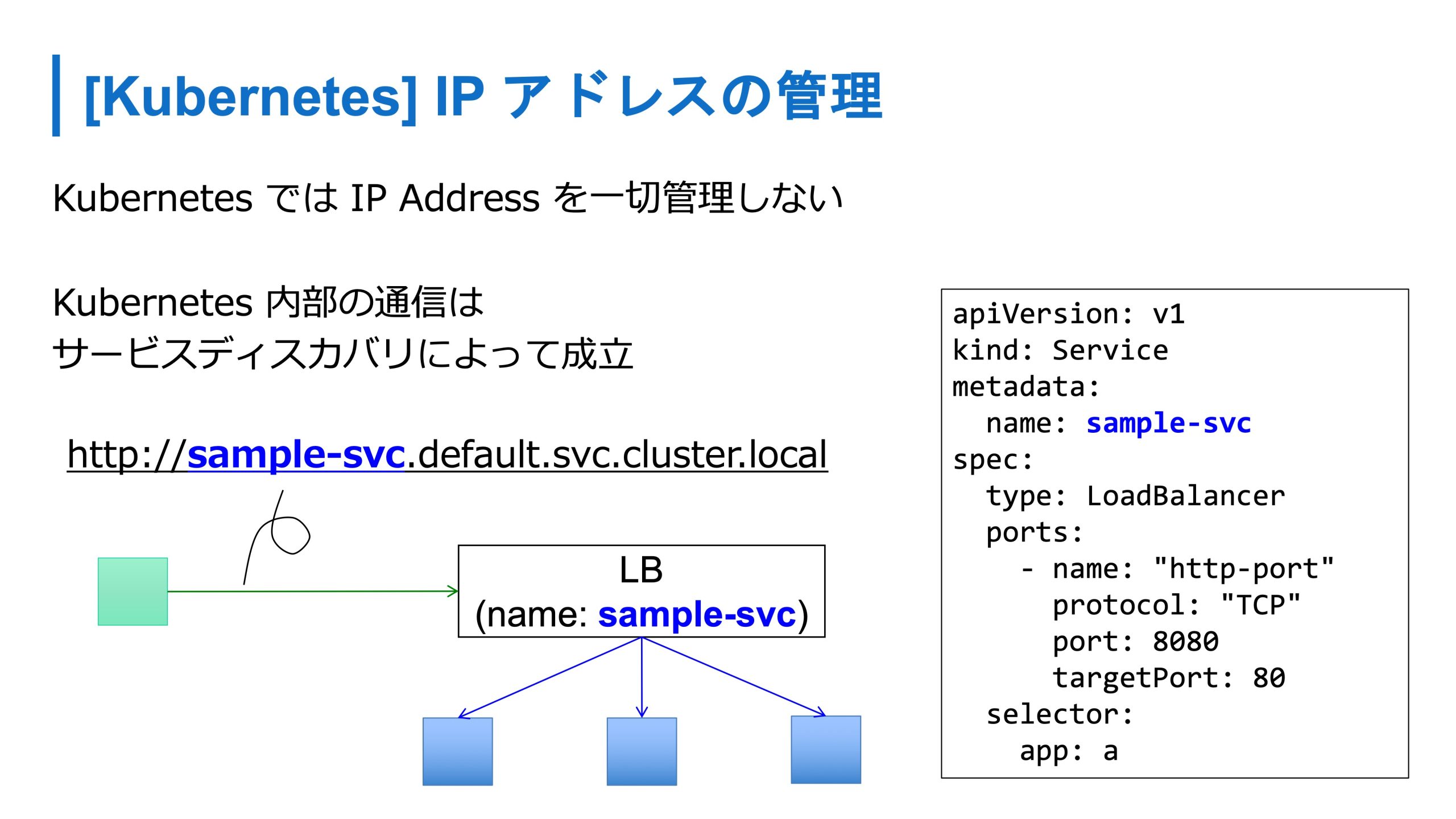
開発者もこの抽象化されたコードを使って操作ができ、IPアドレスは、ロードバランサのIPアドレスなどとかも、このサービスリソースの名前で解決できるので、アプリケーションから通信するときはすべて DNS を経由して、名前で検索できるようになります。
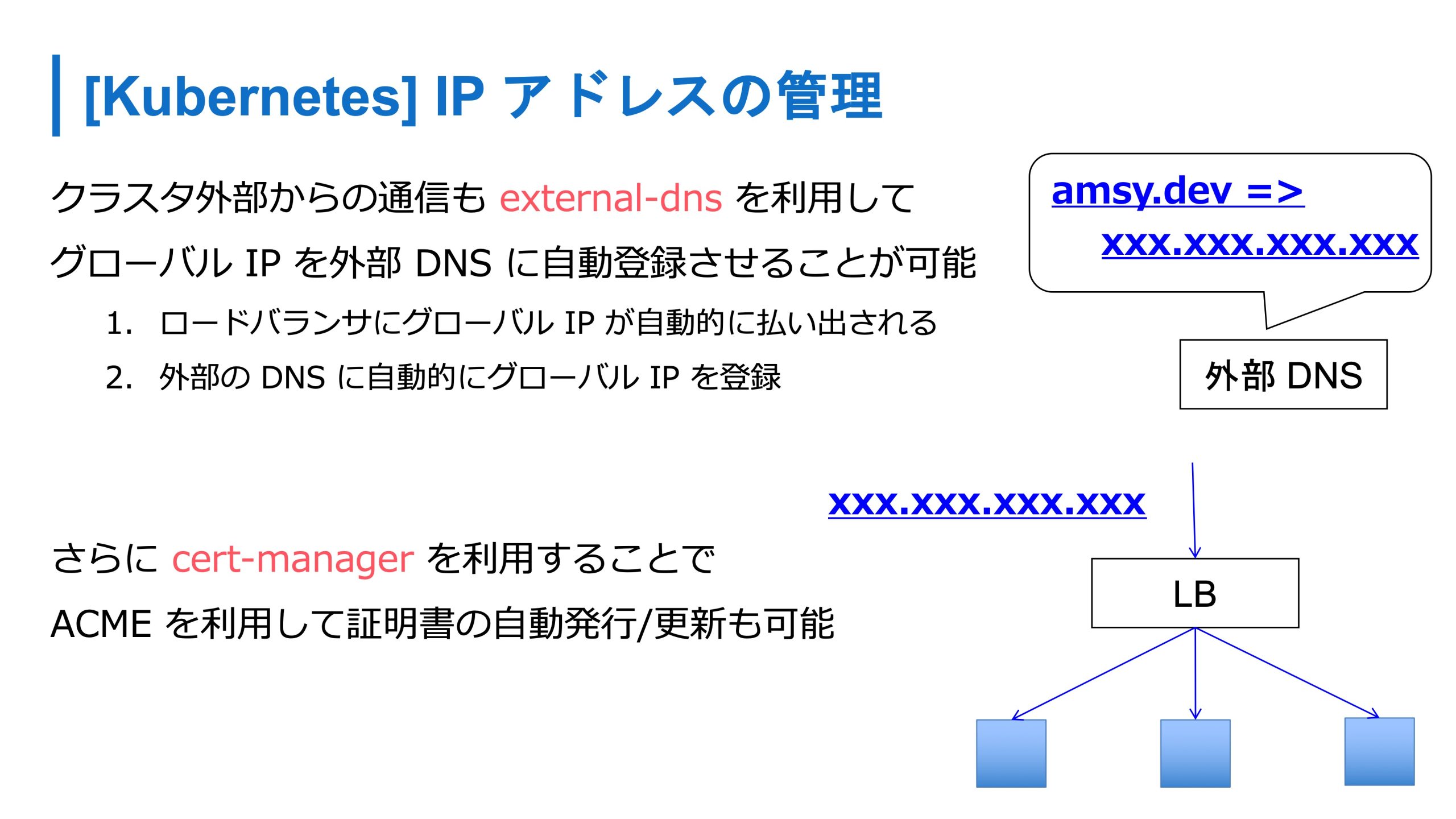
あとは、グローバル IPアドレスとかもExternal DNS を使うと外部の DNS と自動連携することができたり、cert-manager を使うと証明書の自動発行や自動登録も可能になります。

客員研究員
#Kubernetes 完全ガイド 著者、#CNDT2019 #CNDT2021 Co-chair、#cloudnativejp #k8sjp #KubeConJP Organizer、さくらインターネット研究所 客員研究員、CREATIONLINE 技術アドバイザ、3-shake 技術顧問、PLAID




